최적화가 뭘까? 최적화 기법에는 어떤 것이 있을까? 오늘은 경사하강법에 초점을 맞춰 최적화 기법을 알아보자.
용어
Generalization, Underfitting & Overfitting

일반화. 우리는 학습을 시켜서 어느 데이터를 넣더라도 잘 작동하는, 잘 일반화된 모델을 만들고 싶어한다. 그래서 우리는 학습 데이터를 통해 계속 학습을 시키는데 이러면 학습 데이터에 대한 오차는 줄어든다. 그러나 결과적으로 일반적인 데이터에 대한 오차는 어느 시점을 지나면서 점차 커지기 시작한다.
generalization gap이란 이러한 test error와 training error의 차를 말하는데, 어느 정도의 학습이 지나면 이 갭이 커지게 되고 이전에 학습을 마치는 게 중요하다. 참고로 이 갭이 적다고 해서 무조건 좋은 건 아니다. 위의 그림에서는 가장 왼쪽이 갭이 적지만, 에러가 높다. 그 밸런스가 중요한 것!
여기에서 나오는 개념이 바로 underfitting, overfitting이다. 위 그림의 오른쪽, 즉 갭이 큰 부분의 상태를 과적합overfitting이라 하며, 학습데이터에 잘 작동하면서 테스트 데이터에는 잘 작동하지 않는 현상을 말한다.
반대로 왼쪽은 덜 학습된 underfitting이겠지!
Cross-validation
먼저 꼭 전제로 까는 것. 테스트 데이터는 절대로 학습 데이터로 사용되면 안 된다. 조금이라도 쓰이는 순간 그것은 치팅이 된다. 상식적으로 당연한 이야기!
이에 대한 대책으로 나오는 방법 중 하나로 K-fold validation이라고도 부르는 cross validation 기법이 있다(정확히는 cross validation의 기법 중에 K-fold가 있는 식. hold-out 방식도 있다). 이는 학습 데이터를 K개로 나눈 뒤에 그 중에서 일부를 유효성을 검사하는 데이터로 활용하는 기법을 말한다. 테스트 데이터를 학습에 사용할 수는 없지만, 테스트를 해보기는 해야겠다는 거지! 그러한 학습 데이터 내에서 쓰이는 테스트용 데이터를 validation 데이터라고 한다.
가령 10개의 데이터가 있다면, 이를 5등분해서 8개로 학습을 하고 2개로 유효성을 검사하는 것이다.
이를 통해 우리의 모델이 당장의 학습 데이터에만 적합한 것은 아닌지 확인하는 절차를 밟을 수 있다.
Bias and Variance Tradeoff

우리가 모델을 학습시키면서 맞춰나가는 값은 분산과 편향. 뭐가 뭘 뜻하는지는 위 사진만 봐도 알겠지?
우리의 모델은 학습을 하면서 이 둘을 점차 맞춰나간다. 근데 서로 독립적인 변수가 아니라 어느 한 쪽이 줄어들면 다른 한 쪽은 늘어나는 결과가 나온다. 우리는 오차라는 한 값만을 줄이고 있는 것 같지만 막상 보면 그 값이 세 가지(분산, 편향, 노이즈)로 이뤄져 있다는 것이다. 우리가 원하는 것은 좌측 상단의 과녁인데 막상 보면 좌측 하단과 우측 상단의 그림이 계속 나오게 된다는 것. 이를 tradeoff라고 부른다.
참고로 이러한 tradeoff는 학습 데이터에 noise(이게 정확하게 뭘까)가 껴있다는 것을 가정한다. 아무튼 이는 우리의 데이터가 완전히 100퍼센트의 오차 없이 작동하기는 힘들다는 것을 내포한다.

Bootstrapping, Bagging vs Boosting
bootstapping은 끈을 조이는 것을 뜻한다. 통계학에서 주로 쓰이는 용어로 학습 데이터가 고정되어 있을 때 그 데이터를 복원 추출하면서 표본을 만들어 활용하는 기법을 말한다.

그렇게 random subsampling하여 각각의 결과를 모으는 것. Boostrapping AGGregatING 즉 bagging은 데이터를 그냥 하나로 취급하고 다루는 것보다 좋은 성능을 내는 경우가 많다.
그럼 Boosting은? 데이터를 조금 분할해 각각에 맞는 모델을 만들고, 그러한 모델들은 연속적으로 합치는 것을 말한다. (왜 이렇게 할까?) bagging은 각 표본들을 독립적으로 바라본다는 것이 다른 점.
수정
Bagging은 이해하고 있는 것이 맞다. 데이터에서 복원추출해가면서 샘플을 뽑고, 그것을 모델에 돌리는 것을 말한다. 내가 이해하는 바에 따르면 복원추출을 하기 때문에 모든 데이터를 활용하지 않게 될 가능성도 있다. 그렇지만 최소한 각 표본은 서로 독립적이라고 말할 수 있다. 완전한 무작위니까.
한편으로 그렇기 때문에 모든 데이터를 쓰지 않게 될 경우가 발생하며, 그렇기에 각 샘플이 비슷한 데이터로만 구성되는 경우가 많아진다.
Boosting은 모든 데이터를 일단 박아넣는다. 그리고 그 중에서 오답으로 나온 것들을 따로 빼내 샘플로 만들고, 그것을 다시 모델에 적용시킨다. 그렇기 때문에 데이터의 추출 과정에서 이전 시행의 영향을 받게 되므로 데이터의 샘플이 독립적이라고 할 수 없다. 이쪽은 sequantial한 모델을 가지게 된다.
실용적인 경사하강법 기술
경사하강법. loss를 줄이는 방향으로 값을 업데이트해 어떤 최적의 값으로 나아가는 방법. 참고로 이때 최적의 값은 국소적일 수도 있다.
배치 사이즈
데이터를 기준으로 경사하강법에는 3가지 분류가 있을 수 있다.
- Stochastic Gradient Descent
샘플 하나만 뽑고, 그거로 업데이트. 이걸 엄청 반복하는 것. 엄밀하게는 하나의 샘플만 사용 - Mini-batch Gradient Descent
작은 배치를 둬서 그것으로 하는 것. - Batch Gradient Descent
모든 데이터를 한번에 활용하여 하는 것.
실질적으로는 모두 미니배치를 사용한다. 미니 배치는 기본적으로는 컴퓨터의 한계를 고려해서 설정하는 건데, 성능적인 향상을 기대할 수도 있다. 그렇기에 적절한 갯수를 사용하는 게 중요하다.
논문에 따르면 큰 배치 사이즈를 가지면 sharp minimizer에 도달하고, 작으면 flat minimizer에 도달한다고 한다. 이때 우리는 flat을 원한다.

이 그림을 보면 sharp에서는 한 x값에서 train과 test의 큰 차이가 나기도 한다. 우리는 일반적인 성능을 원하기에 flat이 권장된다.
업데이트값
우리는 손실함수 이후에 당연히 편미분을 손으로 계산하지 않는다. 우리가 쓰게 될 프레임워크에 구현된 자동미분 기능을 사용하게 될텐데, 어떠한 방법들이 있어왔는지 한번 보자. 우리가 optimizer를 정해야한다는 것.
Stochastic gradient descent
가장 기본적인 사용법은 결국 일반 경사하강법 방식이다. 미분한 값에 학습률을 곱하고 그것을 뺀다. 이놈의 문제는 이 미분값이 크면 발산해서 학습이 안 되고, 작으면 느려서 학습이 안 된다는 것이다.
Momentum
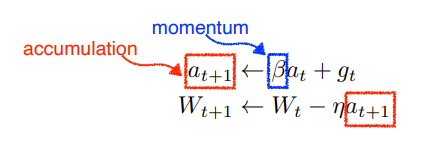
관성 주기. 한마디로 한쪽으로 한번 이동했다면 그쪽으로 조금만 더 이동하자는 것이다. 이전의 정보를 활용하는 것. 모멘텀이라는 하이퍼 파라미터를 두고, 그것으로 업데이트를 같이 한다.
이 놈은 양쪽으로 진동하는 구간 이전에 의도적으로 조금씩 더 이동을 시켜주기 때문에 더 빠르게 극소점으로 나아간다.
Nesterov Accelerated gradient
모멘텀은 양쪽으로 진동하는 구간에 가게 됐을 때 빠르게 극소점으로 나아가지 못하는 문제가 있다. 이 놈이 그걸 해소해주는데 원래 경사하강법은 현재 값에 미분을 하지만 얘는 한번 이동을 한 자리에서 미분을 한다. 그 다음에 값을 갱신하는 방식으로, 아무튼 극소점으로 더 빨리 떨어지게 된다고 한다.
Adagrad
여태의 방법을 모멘텀류라고 퉁치자. 이와는 다른 Adaptive 방법이 있다(그래서 아다가 붙는 거다). 그 시작은 adagrad. 이것은 이전 데이터를 보기는 보되, 여태 데이터가 변해온 정도를 본다. 많이 변하면 적게, 적게 변하면 많이 변화시키고 싶은 것. 그래서 여태 변화한 값을 저장하는 변수 G를 둔다.
근데 이건 또 문제가 있다. 왜냐하면 분모에 G를 두는데 이 값이 점차 커져서 업데이트하는 값이 0에 수렴하고 결국 학습이 점차 멈추게 되는 것.
Adadelta

이전의 놈의 문제, 분모만 계속 커지는 걸 막는다. 이 놈은 G가 시간에 의해 변화되는 정도를 본다. 그것을 보면서 조정을 해주는 것.
RMSprop
이건 윗놈에 학습률을 넣어주는 것. adadelta는 학습률을 사용하지 않기 때문에 그것을 보정해준 것이다.
Adam

현재 가장 무난한 선택지. 모멘텀과 ada를 같이 활용한다!
Regularization
일반화를 더 잘하도록 규제를 거는 기법. 학습이 덜 되도록 방해하여 결과적으로 테스트가 잘 되도록 하는 것이다.
Early stopping
오버피팅의 문제는? 갭이 커지기 전에 일찍 학습을 멈추면 되겠지. 이게 early stopping.
이때 테스트 데이터를 활용해서 멈추는 타이밍을 알아내는 것은 치팅이기에 validation을 쓴다.
Parameter norm penalty
각 파라미터가 너무 커지지 않도록 전체적 차원의 조정을 하는 기법이다. 모든 파라미터를 더해서 나오는 숫자가 작게 만들어준다. 뉴럴 네트워크의 모든 함수를 부드럽게 한다는 의미를 띄게 된다.
Data augmentation
데이터는 많으면 많을수록 좋다. 데이터가 많을수록 모델의 성능은 올라기기에 데이터를 강제적으로 늘리는 방법을 쓸 수 있다. 하나의 사진을 돌려도 보고 대칭시켜 보기도 하고, 흑백으로 바꾸는 식으로 데이터에 변형을 가해서 새로운 데이터로 활용하는 것.
Noise robustness
이것도 비슷하긴 한데, 이건 데이터로 넣는게 아니라 학습 도중에 흔들어주는 방식이다. 중간중간 데이터에 노이즈가 끼게 만드는 것인데, 이것도 신기하게 성능 개선에 도움이 된다.
Label smoothing

이건 데이터를 서로 섞어주는 것. 한 데이터를 가공하는 게 아니라 데이터를 마구 뽑아서 그것들을 하나로 가공하는 것이다.
Dropout
이건 뉴런을 중간중간 0으로 바꿔버리는 것.
Batch normalization
적용하는 레이어, 파라미터를 정규화시키는 것. 레이어가 깊을수록 효과를 발휘한다. 전체 파라미터에 적용하는 방법도 있고 국소적으로 적용하는 방법도 있다.
여기 나와있는 방법들은 왜 성능이 올라가는 것인지에 대한 엄밀한 연구가 이뤄지지 않은 것들이 더러 있다. 그래서 그냥 이런 것들이 있다~ 정도로 알아보면 되시겠다.
- Cross-Validation을 하기 위해서는 어떤 방법들이 존재할까요?
K-fold, Hold-out
- Time series의 경우 일반적인 K-fold CV를 사용해도 될까요?
1)의도치 않은 누수가 발생할 수 있고, 2)데이터 추출의 공정성(무작위성)이 지켜지지 않을 수 있어서 사용할 수 없다. 그래서 두 가지 기법을 쓸 수 있다. 1)Predict Second Half, 2)Day Forward-Chaining. 자세한 내용은 naver..
'인공지능 in 네부캠 AI 4기 > 딥러닝 기본' 카테고리의 다른 글
| Computer Vision Applications (0) | 2022.10.04 |
|---|---|
| Modern Convolutional Neural Networks (0) | 2022.10.04 |
| Convolutional Neural Networks (0) | 2022.10.04 |
| Neural Networks & Multi-Layer Perceptron (0) | 2022.10.03 |
| Historical Review (0) | 2022.10.03 |