과제에 나온 것들을 연습해보고, 직접 구현해보기. 그리고 추가적으로 몇가지 연습을 더해서 파이토치랑 더 친해지기

torch.tensor, torch.Tensor
기본적으로 전자는 함수, 후자는 클래스이다.
tmp = [1,2,3]
A = torch.Tensor(tmp)
B = torch.tensor(tmp)
print(A, B)
print(type(A), type(B))
A = torch.Tensor()
B = torch.tensor()
A = torch.Tensor(tmp, requires_grad=True)
B = torch.tensor(tmp, requires_grad=True)Tensor는 받는 인자가 없더라도 빈 텐서가 생성된다. 또한 자동으로 미분의 대상이 되기 때문에 requires_grad를 인자로 받지 않는다. 또한 Tensor는 int형의 배열을 받더라도 float으로 저장한다. tensor는 정반대.

tensor는 항상 데이터를 복제한다.
torch.add 등의 연산 함수

torch.add는 함수. 하지만 텐서 객체에 메소드로도 있다.

torch.gather 등의 차원을 다루는 함수

dim이 고차원이면 무조건 해당 차원의 첫번째 원소만을 이용하는 듯하다. 차원을 맞춰줘야 사용할 수 있다.

3차원에서 대각선의 위치에 있는 값들을 빼낼 때 사용하는 방법. 웬만해서 dim은 최하위 차원으로 두면 되는 듯하다.

여기서부터는 앞 인자는 내가 몇 개로 나누고 싶은 지를 나타낸다(보장되지 않는다. 보장하고 싶다면 tensor_split을 사용하라). 뒤는 dim으로 내가 싹둑할 차원을 나타낸다.
random 관련

randn은 표준정규분포를 따르는 값을 내준다. 일반적인 rand보다는 확률적으로 정규분포 모양을 그리나봄.
einsum
Einsum 사용하기 | Yeongmin’s Blog (baekyeongmin.github.io)
Einsum 사용하기
Torch나 Tensorflow로 짜여진 코드들을 보다보면 einsum() 연산이 포함되어 있는 경우를 볼 수 있습니다. 아주 가끔 보이는 방법이라 보일때마다 해석하는 법을 찾아보고는 했는데, 이번에 살펴보았던
baekyeongmin.github.io
아주 좋은 글이 있어서 인용. 아인슈타인 합을 줄여서 쓴 것인데, 행렬 연산이 어떻게 될 것인지 문자열로 인자를 넣고, 그 후에 연산할 배열들을 넣는 방식으로 작동한다. 간단한 예시를 들자면 2차원 행렬의 행렬곱을 할 때,
$\Large A_{ik} \times B_{kj} = C_{ij}$
일텐데, 이때 이렇게 진행될 행렬의 연산은 'ik,kj->ij'라고 표시를 하는 것이다. 만약 내적으로 표현하고 싶다면? 'ik,ik->' 뭐 이런 식으로. 이 방법을 잘 알아두면 확실히 복잡한 행렬 연산을 편하게 표현할 수 있을 것으로 보인다. 또한 코드 공유를 할 때도 이러한 표기 덕에 쉽게 이해할 수 있지 않을까.
linalg
선형대수학과 관련된 함수들

보다시피 공식문서에서는 노름을 구할 때 벡터와 행렬을 구분하는 함수를 쓸 것을 권장하고 있다.
다른 놈들도 보려고는 했는데.. 선형대수학의 내용이 너무 많이 등장해서 쉽게 손을 댈 수 없었다. 이러면 어쩔 수 없다.
nn
이것은 파이토치의 블럭을 쌓는 과정을 돕기 위해 존재하는 기본적인 블럭 모듈이다. 이걸 잘 다루는 게 실질적인 파이토치 숙달의 핵심이라고 생각한다.

조금 만져보니까 감이 오는데, 이것도 결국 모듈이다. 결국 모듈들이 이미 차곡차곡 쌓인 방식으로 구현되어있고 빌트인으로 제공되는 함수 따위의 것들도 결국은 다 클래스로 된 모듈.

grad_fn은 미분이 되기 이전의 연산 정보를 담고있는 인자이다. 이것을 이용해서 미분이 진행된다고 한다. linear를 보면 addmm이라 써있는데 아주 정직하게 선형회귀의 식을 생각해보면 될 듯하다. 참고로 미분할 때 미분할 녀석은 output이 벡터 형태여야 한다고 한다.

별난 놈이다. 일단 모듈로 보이는데.. 그냥 똑같은 놈을 만들어주는 모듈인 듯하다. What is the use of nn.Identity? - PyTorch Forums
What is the use of nn.Identity?
CLASS torch.nn. Identity ( *args , **kwargs )[SOURCE] A placeholder identity operator that is argument-insensitive. Parameters args – any argument (unused) kwargs – any keyword argument (unused) Examples: m = nn.Identity(54, unused_argument1=0.1, unuse
discuss.pytorch.org
쓰는 용도는 다양한 듯하다. 완전히 복사를 해주는 놈이니까 변수명을 간단하게 하기 위해 사용한다던가, 하는 식.
nn.Module
이게 정말 많이 쓰게 되는 모듈.
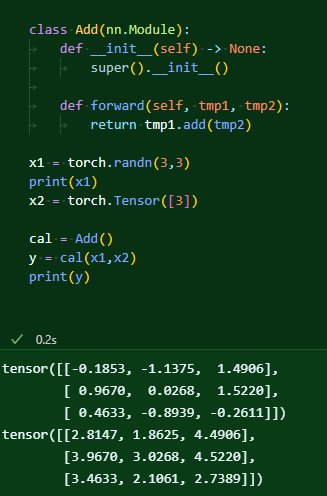
클래스를 많이 사용해본 적 없으니 계속 써가면서 친해져야 한다. 처음에는 이 작동 방식이 너무나 이해되지 않았는데, forward는 부모 클래스로 nn.module을 둘 경우 해당 클래스에 인자를 넣으면 바로 실행되는 메소드이다. backward는 미분을 자동으로 행하는 메소드. 처음에 이게 얼마나 어려웠던지!
왜 super().__init__()이라는 과정이 필요한가? 일단 우리 클래스가 부모 클래스의 기능을 사용할 수 있기 위함이 있을 것이고, 또 부모 노드의 __setattr__를 호출하기 위함이라는 이야기가 있다.
def __init__(self) -> None:
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters: Dict[str, Optional[Parameter]] = OrderedDict()
self._buffers: Dict[str, Optional[Tensor]] = OrderedDict()
self._non_persistent_buffers_set: Set[str] = set()
self._backward_hooks: Dict[int, Callable] = OrderedDict()
self._is_full_backward_hook = None
self._forward_hooks: Dict[int, Callable] = OrderedDict()
self._forward_pre_hooks: Dict[int, Callable] = OrderedDict()
self._state_dict_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_pre_hooks: Dict[int, Callable] = OrderedDict()
self._load_state_dict_post_hooks: Dict[int, Callable] = OrderedDict()
self._modules: Dict[str, Optional['Module']] = OrderedDict()
def __setattr__(self, name: str, value: Union[Tensor, 'Module']) -> None:
def remove_from(*dicts_or_sets):
for d in dicts_or_sets:
if name in d:
if isinstance(d, dict):
del d[name]
else:
d.discard(name)
params = self.__dict__.get('_parameters')
if isinstance(value, Parameter):
if params is None:
raise AttributeError(
"cannot assign parameters before Module.__init__() call")
remove_from(self.__dict__, self._buffers, self._modules, self._non_persistent_buffers_set)
self.register_parameter(name, value)
elif params is not None and name in params:
if value is not None:
raise TypeError("cannot assign '{}' as parameter '{}' "
"(torch.nn.Parameter or None expected)"
.format(torch.typename(value), name))
self.register_parameter(name, value)
else:
modules = self.__dict__.get('_modules')
if isinstance(value, Module):
if modules is None:
raise AttributeError(
"cannot assign module before Module.__init__() call")
remove_from(self.__dict__, self._parameters, self._buffers, self._non_persistent_buffers_set)
modules[name] = value
elif modules is not None and name in modules:
if value is not None:
raise TypeError("cannot assign '{}' as child module '{}' "
"(torch.nn.Module or None expected)"
.format(torch.typename(value), name))
modules[name] = value
else:
buffers = self.__dict__.get('_buffers')
if buffers is not None and name in buffers:
if value is not None and not isinstance(value, torch.Tensor):
raise TypeError("cannot assign '{}' as buffer '{}' "
"(torch.Tensor or None expected)"
.format(torch.typename(value), name))
buffers[name] = value
else:
object.__setattr__(self, name, value)그럼 한번 nn.Module의 __init__뭐하는 놈인지를 보자. 당장 봤을 때는, 속성 선언하는 것밖에는 안 보이는데, setattr를 보니까 뭔가 init 관련된 것이 보이기는 한다.
이걸 정확히 파악하려면 일단 매직 메소드에 대한 파악도 필요할 것 같다.

! 이런 뜻이었다..! 즉, 내 클래스에서 init을 할 때 setattr가 발동된다는 것. 아직 완벽하게는 이해를 하지 못 했지만, 부모 클래스로 결국 뭔갈 지정해놓은 이상, 자식 클래스에서 속성을 선언할 때 부모에 있는 속성이 필요시된다는 것 아닐까? 그래서 부모의 setattr로까지 가서 문제를 일으킨다는 것.
As per the example above, an __init__() call to the parent class must be made before assignment on the child.
doc에서도 정확하게 명시를 해주고 있다.

모듈을 연속적으로 만들고 싶을 때 사용한다. 확실치는 않지만, 모듈을 적을 때 인자로 적는 것은 가능하지만 ,이후에 이 Sequantial을 쓸 때 인자를 전달하는 것은 불가능한 것 같다. 종속된 하위 모듈들의 forward에 인자를 전달하는 게 불가능하다는 것. Add의 forward는 위에 예시와 같이 2개가 필요한데 그것을 전달할 방법은 없어보였다.

하지만 다른 예시들을 보면 인자가 하나 들어가는 것은 가능한 것 같다. 근데 Add은 인자가 두개 필요한 걸 뭐 어쩌라고.. 하나 줄이면 또 하나 줄였다고 입을 턴다. 에라이 관둬라 관둬..
Sequantial은 순서가 정해져있지만, Modulelist나 Moduledict를 사용하면 인덱싱이 가능해져서 내가 원하는 순서로 작동하게 코드를 짤 수도 있다. 잘 쓰일지는 모르겠다.
nn의 모듈을 사용하면 모듈이 해당 모듈의 하위로 들어간지의 여부를 판별할 수 있게 된다.
parameter

파라미터를 등록하면 해당 변수를 앞으로 미분할 대상이라는 것을 확실히 할 수 있다. 보다시피 파라미터 관련 메소드를 토해 접근할 수도 있게 되고, 미분의 대상으로 설정된다. nn에 구현된 layer를 쓰게 된다면 이걸 직접 쓸 일은 없을 것이라 한다.

Parameter처럼 쓸 수는 없고, register를 사용해 버퍼를 만들 수 있다. 참고로 register로 파라미터를 만드려면 아무 값이나 넣을 수는 없고 이미 올려진 파라미터만 사용할 수 있는 듯하다.

register는 객체 생성 이후 바깥에서도 사용할 수 있다. 이전 예시에서 봤듯이 그냥 buffers()나 named_(이건 해당 변수의 이름까지 같이 반환)를 쓰면 제네레이터가 생성된다. 그걸 활용해 print를 해보았다.

직접 파라미터나 버퍼를 만질 일은 없을 이유에 대한 예시. 이미 만들어진 layer를 많이 쓰게 될 것이고, 그런 것들은 알아서 다 지정이 되어있다.

__dict__를 통해 가지고 있는 온갖 정보들을 확인할 수 있다. 아래에 보면 hook이 있는데, 이것을 통해 내가 해당 모듈이 작동될 때 그것에 대해 작동하고 싶은 함수를 우겨넣을 수 있다. 이 함수는 결과값에도 변화를 줄 수 있다.
이외

내가 만든 함수를 모듈에 전체 적용할 수 있는 기능. apply!
'인공지능 in 네부캠 AI 4기 > 파이토치' 카테고리의 다른 글
| PyTorch Troubleshooting (0) | 2022.10.01 |
|---|---|
| Hyperparameter Tuning (0) | 2022.10.01 |
| Multi-GPU 학습 (0) | 2022.09.30 |
| Monitoring tools for PyTorch (0) | 2022.09.29 |
| 모델 불러오기 (0) | 2022.09.29 |