numba.. 포기

무척 안 좋은 소식. 생각보다 넘바의 활용처가 너무나도 제한적이다. 그냥 jit을 데코레이터 씌울 수만 있다면 괜찮다고 생각했는데, 웬걸 거기에서부터 막히기 시작했다. docs(버전에 따른 최신화가 전혀 안 돼있다)를 뒤져가면서 보니까 jitclass라는 것으로 클래스를 감쌀 수 있다는 것 같아서 시도해봤는데, 이 놈은 또 안 속에서 사용되는 속성들에 대해 타입을 명시해줘야 하는 모양이다. 그런데 그 타입이 dict일 때 어떻게 명시해줘야 하는지 잘 나와 있지 않다.

애초에 numba.typed.dict라는 게 존재하지를 않던데.. 그렇다고 dict만 꼴랑 쓴다고 해결도 안 되던데.. 아무튼 사용법이 여간 까다로운 게 아니다. 심지어 그러면서 파이썬의 모든 기능들을 처리해줄 수 있는 것도 아니라고 하니, 사용법을 찾는데에도 시간이 걸리는데 실제로 사용 가능한 것인지도 모르겠는 애매한 상황이 되어버렸다.

이게 돌아간다는 것은 알 수 있었다. 근데 init에 인자를 넣는 순간 그 인자가 어떤 타입인지를 알려주어야만 하는 듯하다. 메소드의 안쪽에 함수를 만들어서 그 함수를 jit으로 감싸는 방향을 생각해보기도 했으나, 그것도 원하는 대로 작동되지 않았다. 아무래도 그 함수도 인자로 넣는다던가 하는 식으로 하는 것을 numba는 원하는 듯하다.
이걸 더 깊게 들어가는 것은 너무 힘든 일이 될 것 같다. 못할 건 없지만, 굳이 꼭 해야할까하는 고민도 생긴다.
repsys 깃헙 탐색
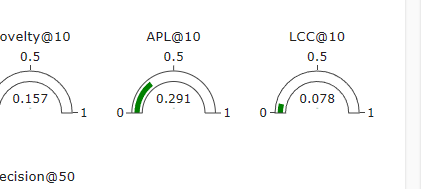
내가 이 웹 페이지를 보면서 가장 궁금했던 것은 바로 저 apl과 lcc라는 지표였다. 다른 놈들은 얼추 알겠는데 얘네는 본 적도 없는 놈들이라 어떻게 구성되는 것인지 너무 궁금했다. 그래서 깃헙을 통해 이 지표들을 찾을 수 있지 않을까 생각했다.

결과적으로 깃헙으로는 찾을 수 있는 방법이 없다. 정말 repsys 자체는 데모 페이지일 뿐이더라고. 저 지표는 그냥 사진 파일일 뿐이고 실제 깃헙 코드에는 해당 지표를 계산하는 코드가 없는 듯하다. 암만 찾아봐도 코드가 안 나오던데 일단 깃헙으로는 찾을 수 없는 것으로 결론 짓고, 나머지 코드를 조금 참고해보자.

diversity나 내가 아는 지표들이 나오는데, 이 지표들은 어떻게 계산되고 있는 것일까? 가장 먼저 알아야 할 것은 X_distance.

뭔가 하니 scikit learn에 있는 놈이었다. 어떤 행렬을 받으면 그 행렬의 쌍별 거리를 계산해주는 놈이다. 두 인자를 그 두 놈 간의 거리를 계산한다.

조금씩 단추가 메꿔진다. 한 행렬을 집어넣어서 그 행렬 속의 쌍별 거리를 계산해준다. X_train은 뭐 당연히 그냥 rating 행렬인 듯하고.

meshgrid는 두 인자를 받았을 때 각 쌍을 만들 수 있는 형태로 복제한 행렬을 반환한다. 위 코드에서는 idx, idx를 넣으니 말그래도 쌍을 만드는 것이라 보면 되겠다.

ㄷㄷ 지린다.. 이런 식으로 쌍을 만드는 방법이 있군.
마지막으로 vectorize는 일종의 함수를 만드는 일이다. 내가 정의한 함수를 넣고, signature로 입력과 출력의 형식을 써준다. 저 방식으로 쓰는 것을 pyfunc 형식인가 뭔가가 있는 모양인데, 아무튼 n만큼 들어가서 스칼라로 나온다는 것을 명시해주는 모양. 그럼 이제 저걸 함수처럼 쓸 수 있게 되는 것이다. 원래 그냥 함수 f는 idx 하나만 들어가는 형식이었지만, vectorize 함수 덕분에 벡터를 넣을 수 있게 된 것이다. 보아하니 들어가는 것은 각 유저별 topk개의 추천리스트가 들어간다. 아니다. 그렇지는 않을 것 같다. 지금의 식을 봐서는 한 유저 당 값이 들어가도록 되어 있다.

뭐.. 내가 직접 돌려보지 않는 이상 확실한 것은 아니지만, 바깥에 for문으로 되어 있는 것은 아마 유저별일 가능성이 높다고 본다. 정리하자면 유저별 diversity를 계산하고 있는 것이다. 아주 재밌는 방법으로! 기본 거리는 cosine을 이용한다.

여기에는 serendipity는 없다. 다만 novelty는 max novelty를 통해 값을 0과 1사이로 맞춰준다. 이건 우리도 똑같이 구성되어있다. 그것보다는 인기도를 정의하는 부분이 조금 다른 것 같은데.. X_train.shape[0]이면 유저 수로 나누는 게 아니라 전체 상호작용 수로 나누는 것 같단 말이지. 안 그래도 이전에 내가 popularity와 famousness를 구분하여 생각했던 부분과 관련되는 듯. 사실 진짜 인기도라고 하면 이쪽이 정말 맞다고 생각한다. 단순하게 유저들이 아는 것만으로 novelty를 따지는 것보다는 인기도의 반대라고 생각하는 게 지표로서도 의미가 있지 않을까 생각하는 편이다.
문득 다시 보다가 알게 됐는데, 출력값이 ndarray라면 유저별로 모두 계산된 값을 내뱉는 것은 맞는 것 같다. 바깥 for문은 각 모델을 순회하는 의미라고 보면 될 듯. signature에 출력을 ()로 걸어놔서 괜히 더 헷갈렸네.
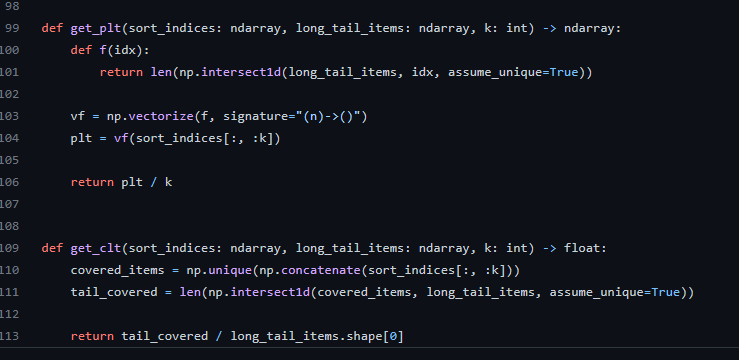
일단 어느 정도 내용 탐색은 마친 것 같다. 다른 함수들을 보는 것이 또 의미가 있을 수도 있으려나, 싶어서 찾은 부분이 이것인데 이것도 인기도와 관련된 지표로 보인다.
plt는 롱테일에 해당하는 아이템 리스트를 가지고 있다가 그 아이템이 추천된 비율을 따진다. pl.. 설마 이게 apl인가? Average Percentage of Longtail. 맞는 것 같다. 이것은 유의미한 지표가 될 수 있는가? 다른 것과 겹치지는 않는가?
다음 clt는 아마도 Covered LongTail. 출력이 혼자 float이다. 롱테일에 속하는 녀석들이 얼마나 커버됐냐를 따지겠다는 것이네. 아까를 생각해보면 LCC가 이놈과 관련 있을 것 같다. Longtail Covered Count? 이건 너무 짜깁기인가?ㅋㅋ 그래도 관련 있는 것이라는 생각은 든다.
그럼 여기에서 지금 찾은 새로운 이 지표들. 무슨 의미가 있는 조금 고민을 해보자. 일단 여기에는 serendipity가 없는데, 여기보다는 우리가 더 유의미한 지표를 하나 보여주고 있는 것 같아서 살짝 좋네. 롱테일 관련한 지표가 두 개나 있는데, 사실 이것들은 롱테일에 초점을 맞추기는 하나 다른 지표들을 통해 어느 정도 감안이 가능하다고도 생각한다. novelty가 애초에 인기도의 역이기 때문에 novelty가 높으면 두 지표 모두 양의 방향으로 영향을 받을 것이다.
라고 생각하고 봤는데, repsys 페이지를 보니 생각보다 APL은 완전히 둘과 같지는 않았다. 더 민감하고, 어쩔 때는 다른 놈들이 내려가는데 올라갈 때도 있다. LCC는 coverage를 완전히 따라간다.

novelty와 apl이 안 따라가는 모델은 svd였다. 이놈만 아니면 다 novelty 따라가는데, 이 놈을 보니 완전히 따라가는 것은 아닐 수도 있겠다는 생각이 들었다.
하지만 역시 생각으로는 조금 이상한 걸. 어떤 아이템의 novelty 값이 크다는 것. 그것은 상호작용이 적다는 것을 의미하고 그것은 곧 롱테일에 속한다는 것을 의미한다. 그러니 apl과의 차이를 두자면 novelty는 롱테일에 속하는 것을 점수로 환산하여 표현하는 것이고, apl은 롱테일에 속하는 비율을 따진다는 것이다. 둘의 값은 비슷할 수밖에 없다고 생각되는데 꽤나 차이가 나니 내가 저 지표를 잘못 추측한 것이거나 아니면 내가 놓치고 있는 부분이 있을 수도 있다. 아니면 정말 내 추측이 맞음에도 둘은 유의미한 차이를 보일 수 있는 지표라는 뜻일 수도 있다. 그렇다면? 지표로 추가하는 것이 나쁘지 않을 수도 있겠지. 이건 후보군에 올리자.
스포티파이 조사

본인들의 discover weekly에 관한 이야기
추천 대회를 열었던 모양이다.
Algorithmic Responsibility - Spotify Research : Spotify Research (atspotify.com)
Algorithmic Responsibility - Spotify Research
Research in algorithmic responsibility at Spotify combines machine learning research with social science to ensure high quality data decisions and equitable algorithmic outcomes. We carry out in-depth research, perform product-focused case studies, as well
research.atspotify.com
스포티파이 R&D. 논문과 연구에 대한 글들이 있고, 대회에서 쓰인 데이터셋을 볼 수 있다.
회고 및 다짐
누굴 미워하는데 시간을 쓰는 것만큼 낭비스러운 일이 또 없다. 마음대로 되는대로 살 수 있다면 부처 아니겠냐마는, 좋은 거 보기 살기도 바쁜데 안 좋은 기운만 챙겨봐야 더 안 좋아질 뿐이다. 유하게, 유하게 살자고.
하지만 난 선을 넘지 않겠다. 역시 나는 그 선을 넘을 수 없다.
'일지 > 네부캠 AI 4기(22.09.19~23.02.14)' 카테고리의 다른 글
| 20230125수 (0) | 2023.01.26 |
|---|---|
| 20230123월-스포티파이 공부 (0) | 2023.01.24 |
| 20230120금-최종10, 레콤비 (0) | 2023.01.20 |
| 20230119목-최종9, 수내 오프라인 (0) | 2023.01.20 |
| 20230118수-최종8 (0) | 2023.01.19 |