부캠 시작한 이래로 늦잠 잔 건 처음이다. 알람도 못 듣고 퍼질런 잔 듯..덕분에 피로는 많이 풀린 것 같다!
데일리 스크럼
PM, 모더레이터를 격주로 하는 건에 대하여. 격주로 하게 될 경우 모두가 한번씩은 하게 될 것.
월요일 아침까지 코테 풀기.

BERT에 대한 간략한 이해. 사전 훈련 언어모델. 키워드들을 간략하게 캐치하고 이후에 세심하게 공부해보는 것으로.
EDA
미션 2에 있었던 누적 정답률을 구하는 것은 꽤 의미가 있을 것이다. 다만 이것은 시험 별로 하는 것이 좋을 수도 있다.

일단 테스트와 학습셋을 합쳐서 사용한다.

풀린 기준으로 문항 갯수 카운트. 이는 두 가지를 시사한다. 일단 시험의 문항수가 적다는 것과, 뒤로 갈수록 문제를 덜 풀 수 있다는 것.


그럼 궁금하니 또 찍어봐야지. 각 시험에 대해서, 최소한 한 명이라도 문제를 끝까지 푼 적이 있다고 가정하면 각 시험의 문항의 갯수를 구할 수 있다. 그래서 그래프로 나타낸 모습이다. 확실히 문항 수는 대체로 5개에서 8개 사이로 분포를 하고 있는 모습이다.
새삼 드는 생각은 풀이 수가 적은 문항 갯수를 가진 시험들의 정답률은 어떻게 될까?
일단, 아까 시사점부터 보자면 6번 문항부터 풀이 갯수가 줄어드는 것을 볼 수 있는데 아무래도 시험 문항 갯수 자체에 많은 영향을 받는 것으로 보인다. 시험의 난이도 때문에 중도 하차하는 케이스가 분명 존재할 것으로 생각된다.

그럼 각 시험 별로 최대 문항의 갯수를 일단 저장해주고, 유저가 그에 도달했는지 확인해볼 수 있지 않을까?
이걸 제대로 확인하려면 재시험을 치루는 것도 확실하게 구분해주면 좋을 것 같지만, 일단 해보자.
문항 수가 다른지 먼저 체크. 이것부터 확실히 하자.
피어세션
내가 생각하고 있던 부분에 대한 오차를 수헌이 형이 짚어줬다. 아무래도 이건 더 고민해봐야 할 듯.
임베딩에 대한 설명과, 베이스라인 코드가 작동하는 방식, 그리고 어떻게 수정될 것인지에 대하여.
범주형 결측치는 np.nan, 수치형에 대해서는 0이든 뭐로든 채워라.
수치형에 대해 스케일링(minmax, 로그 등)을 하라. 범주에는 바이닝을 하라. 대충 시각화하고 알아서 처리하기.
z score로 통일하기. layernorm은 행 단위로 정규화. 통상적으로 층 통과 이후. batchnorm은 피쳐별로 정규화를 진행(앞서 진행가능).
유저 id는 학습에 쓰이지 않는다. 인덱스로 적용될 뿐. 이것은 부스팅을 쓰더라도 마찬가지.
컴터가 한번 꺼졌는데, 뭐가 어떻게 된 건지 EDA했던 게 날아갔다. ㅂㄷㅂㄷ.. 기억하기로 vscode는 저장을 안 해도 어느 정도 따로 저장을 해주는 것 같던데.
EDA

max값이 5인 것처럼 튀어나오던 060001시험에서 7번째 문항이 확인됐다. 아무래도 내가 원하는 내로 코드가 작동하고 있지 않다는 것을 뜻한다.

흠.. 다시 곰곰히 생각해봤는데 맞는 것 같기도 하다. 위에 방금 착각했는데, groupby를 통해 정렬이 이뤄지면서 맨 첫번째에 놓인 테스트id는 010001이더라고. 그리고 그것을 계속 확인해보고 있는데 아무래도 5를 넘어가는 값이 없다.

보다시피 이러하다. 처음 형의 말을 들을 때는 나도 파악하지 못 했는데, 아무래도 max는 내가 원하는대로 잘 작동하고 있는 것 같기는 하다.

수헌이 형이 올려준 코드가 있는데, 이것은 정확하게는 시험을 더 큰 범주로 나눴을 때의 값이라고 생각한다
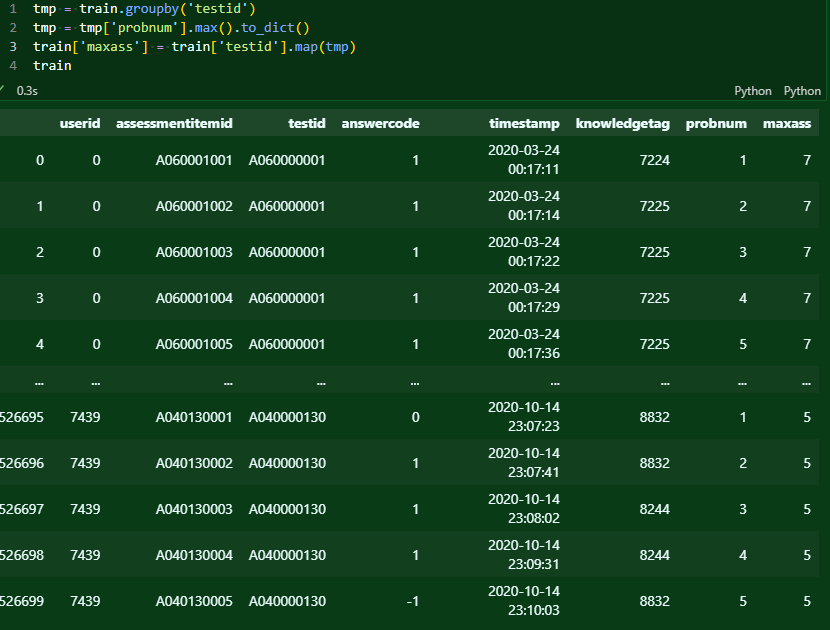
각 시험의 최대 문항에 대한 피쳐를 추가했다. 그럼 이것을 통해 정말 maxass(그 ass 아니다 assessment다)가 정말 최대 문항을 나타내는 것이 맞는지 체크할 수 있다.

보다시피 깔끔하다.

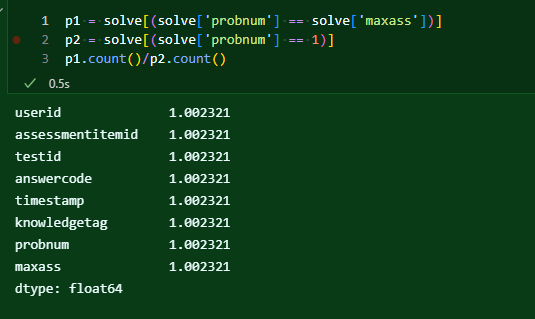
415300번, 시험은 완풀되었다! 마지막 문제를 푼 사람을 카운트하는 것이 시험을 모두 풀었다는 것을 나타내는 지표가 될 수 있다면, 문제 1번을 푼 것이 시험을 도전했다는 것의 지표가 되어도 괜찮지 않을까?
하여 둘을 구하고 비율을 살펴보려니까

이러한 결과가 나온다. 당연히 끝까지 푼 갯수가 적을 것이라 생각했고, 당연히 해당 값은 1보다 작은 값이 나와야 할 텐데..? 내가 또 뭔가를 잘못하고 있는 것일까?
그러니까 지금 이 값은, 1번 문항이 풀어진 갯수보다, 최종 문항이 풀어진 갯수가 더 많다는 것을 뜻한다.
몇 가지 가능성이 있기는 하다. 시험이 수업용으로 활용되고 있어서 교사가 애들한테 특정 문항만 풀라고 지시하고 있어 실제로 문제를 푸는 것이 엉망인 것. 아니면 애들이 쉬운 문제는 성이 안 차서 건너뛴다는 것(..). 아마 마지막이 가장 그럴싸한데, 틀렸거나, 맞혔거나, 상대적으로 난이도가 어렵거나 더 중요한 마지막 문제를 애들이 다시 푸는 것.
이것을 확인하려면 해당 값들의 중복 정도를 확인해보면 되지 않을까 싶다. 그러기 전에 잠깐, 이것을 파헤치는 것이 어떤 의미를 가지고, 어떻게 적용할 수 있는지도 생각해봐야 할 것 같다. 일단 이 경우가 맞다면, 재시험을 보는 방식이 생각보다 자유롭다는 것을 알 수 있다. 굳이 모든 문제를 다시 풀지 않아도 된다는 거잖냐. 조금 더 나아가면 다시 풀리는 문제들은 확실하게 중요도를 높게 평가받았다고 생각해볼 수 있을 것이다. 그렇다면 이는 문항에 대한 가중치를 고려하는 요소로 활용될 수 있다. 거기에다가, 내가 처음 보고 싶었던 것은 중간에 문제를 안 푸는 케이스인데, 어차피 이를 위해서는 중복을 제거할 필요가 있다.오케이. 나름 의미가 있는 것 같다.
그나저나 이러면 기록되어있는 문항이 진짜로 최종 문항이라고 확신을 할 수가 없겠다.

8천번 가까이 중복이 발생하고 있다. 그러고보니 알았는데, 예측해야 할 값도 같이 고려되고 있는데, 이건 추후 수정해줘야겠다. 아니 근데 이제 보니까 저 1번 놈은 뭐저리 조직적으로 틀렸냐..? 순서대로 마지막 문항인 6번만 틀렸었네? 그리고는 바로 다시 맞췄고. 한번에 맞추기 어려운 문제였고, 이후 공부를 해서 깔끔하게 통과했다?

제법 아다리가 딱딱? 그럼 이 중복들을 다 제거하면? 나는 내가 처음 생각했던, 도전했으나 결국 최종을 풀지 못한 것에 대한 수를 알 수 있는 것인가? 이 역시 석연치 않다. 명확하게는 설명이 안 되는데, 다시 풀었는데도 다시 최종을 도전하지 못한 사람이 있을 수도 있는 것 아닌가?

음? 여전히 내가 예상하는 결과가 나오질 않는다. 진짜 그냥 내가 코드를 이상하게 짜고 있는 것인가?
회고 및 다짐
수헌이 형과 이야기하면서 내가 생각하는 방향과 이에 대한 해결을 모색해보았다. 일단 내 코드가 문제는 없는 것으로 의견을 모았고, 왜 이러한 결과가 나오는지에 대해서 고민을 하면서 우리가 사용하는 데이터에 대한 이해를 조금 더 하고자 구글링을 하기도 했다. 아이스크림 홈런 데이터. 대충만 봤을 때는 어째서 마지막 문항의 데이터가 더 많은 것인지 이해하기는 힘들었다. 아주 근소한 차이이기 때문에 큰 차이가 아니라고 생각할 수도 있을 것 같다만, 이런 상태가 되는 마땅히 납득가는 이유가 없어 껄끄러운 것도 사실이다.
일단 내일 오프라인 미팅이니 내일 만나서 더 자세하게 이야기해보자고. 노트북이 불편해서 자세히 필기를 못하고는 하는데, 이를 조금 개선할 방법이 필요할 것 같다. 그리고 당장 내일 멘토 미팅을 알차게 보내기 위해서 빠르게 숙제를 해볼 필요도 있다.
'일지 > 네부캠 AI 4기(22.09.19~23.02.14)' 카테고리의 다른 글
| 20221123수-dkt8, 컴퍼니데이1 (2) | 2022.11.24 |
|---|---|
| 20221122화-오프라인팀미팅, 멘토링, 오아, dkt7 (4) | 2022.11.23 |
| 20221120일-밑러닝 준비, 팀미팅, 리트코드 (0) | 2022.11.21 |
| 20221118금-dkt5, 술페셜, 미션~4 (2) | 2022.11.18 |
| 20221117목-dkt4, 미션1~3 (5) | 2022.11.18 |