데일리 스크럼
깃헙 연습을 해보는 게 필요함. 브랜치를 어떻게 따고, 풀 머지하는 방법. 메인을 유지하면서 업데이트는 브랜치를 파서 풀리퀘를 하는 식으로 해야함.
오늘부터 대회가 시작된다. 제출이 가능해졌다! 제출을 간단하게라도 하면서 감을 잡는 과정이 필요하다.
앙상블을 하면 좋을 것 같다. 이것은 제출해야만 확인할 수 있는 요소. 이것을 직접 검증셋을 만들 수 있으면 좋을 것.
stratified를 해보는 것이 좋을 것으로 보인다. 제출을 해야만 앙상블을 확인할 수 있는 것은 힘들다. 그러니 적극적으로 검증셋 나누는 작업을 해볼 필요가 있는 것 같다.
기본 베이스 코드를 돌려서 뜯어보니 음수나 1을 넘어가는 값이 있다.

제출할 때, 간단하게 AUC를 기록하라.
학습은 신나게 진행해두고, 예측할 때는 만들어진 모델을 가져오는 것 같다. 뭔가 이상해서 코드를 더 뜯어봐야 한다.

train.py를 실행하여 학습을 진행하고 inference.py를 통해 예측을 진행하는데, get_model을 쓰면 학습되지 않은 모델을 쓰는 격이다. 이를 load로 수정해야 한다.
오늘 내가 개인적으로 해볼 것은 스페셜 미션 1. 팀적으로는 베이스라인 코드를 통해 학습을 진행한 것을 제출해보기.
모델 돌려보기

일단 기본 에폭이 적은 것을 확인했다. 저번 대회 때 CNN_FM을 생각하면 에폭을 늘려서 로컬 미니멈을 탈출하는 방향을 생각해볼 수 있겠다. 워낙 무거운 모델이라 들어서 함부로 배치 사이즈를 늘리지는 못했다.
일단 돌려봐야 무슨 느낌인지 조금씩 감이 오기 마련이다!

생각보다 학습 속도가 엄청 빠르다. 처음에는 느린데, 막상 학습은 빠르게 이뤄지는 이상한 녀석. 그런데 중간에 얼리스타핑이 일어난다. 내가 보기엔 아직 학습이 충분하지 않는데 저 혼자 33에 멈춰버리니 원.. 아무래도 내가 조금 더 인자를 추가적으로 줄 필요가 있겠다.

조금 더 배치사이즈도 늘려줬다. 학습이 원체 빠르길래 더 힘을 줘보려고 시도 중.

맞았다가 틀렸다가 이렇게 차이가 심하단 말인가? 이건 학습률이 클 때 일어나는 현상 아닌가?

이야아 부하가 걸릴 때까지 아무거나 마구 시도해보자! 내 컴퓨터 아니다!

요런 문제가 발생했다.

그래서 이렇게 바꿔줬다.

아직은 정확한 해석이 안 된다. 검증 정확도는 점점 수렴하는 모습을 보이고, 학습 정확도는 여전히 날뛴다. 그리고 어떤 것도 지금 lstm보다 좋은 결과를 내지 못하고 있다. 다만 학습 auc가 상향된 것은 보이는데 이게 좋은 것인가 하면 검증 auc 때문에 걸린다.
일단은 여기까지. 당장은 감 잡는 정도니까 지나치게 몰두하는 것도 의미가 그다지 없다. 그냥 어떤 인자가 어떤 것을 나타내는지 정도만 알아도 충분하다.

예측을 진행하려는데 꼬라지를 보니까 학습할 때처럼 인자를 다 전달해야 하는 모양이다.

여전히 개차반으로 예측을 진행했다. 솔직히 그냥 마음 편하게 마지막에 시그모이드 한 잔 올리고 싶다.
validation에 관하여
이건 강의에서도 이전에 나온 적이 있으니 참고해보는 것도 좋겠다.
k-fold 검증은 k개로 데이터를 분할한 후에 k번, 각 나눠진 데이터를 순차적으로 검증셋으로 활용하여 평가하는 방법이다. k번 한 후에 MAE(평균 절대 오차)를 내서 오차 평균을 낸다.
과적합을 막을 수 있고, 학습이 덜 되는 지점을 잘 파악할 수 있다.
그런데 데이터가 편향될 경우 유효하지 않을 수 있다. 즉 데이터 구조가 앞에는 0이 많고 뒤에는 2가 많다면 나눠서 학습할 때 이것 때문에 제대로 학습이 이뤄지지 않는다는 것. 이 경우에는 stratified를 붙여서 쓴다. 일단 데이터를 무작위로 섞는 것을 말한다. target 데이터의 비율을 일정하게 유지한다.

하는 방법 자체는 간단한 듯 하다.

테스트 데이터를 보고 있는데, 어차피 -1에 해당하는 값만 이 놈이 예측을 진행하는 것이니까 -1 한 칸 위에 놈들을 -1처리하고 진행하면 우리 자체 검증이 가능한 것 아닐까 싶은 생각이 든다.
그리고 이거, 시간 순으로 정렬되어 있다. 당연히 사람 순으로 정렬되어 있을 것이라 생각했는데.
스페셜 미션1

간단한 정리. 유저와 태그는 이미 라벨 인코딩이 돼있는 격이다. 자체적인 전처리는 필요 없을 듯하다.

이건 어디까지나 학습셋을 기준으로 하고 있다는 것을 명심하자.
우리의 모델은 무엇을 학습해야할까? 특정 유저의 실력? 특정 문제의 난이도? 문제 풀이 시간에 따른 정답률?
테스트셋과 비교해서 콜드 스타트나 그런 요소를 확인해볼 필요가 있을까? 태그 자체는 확인해보는 게 좋을 것 같기도 하다. 그러나 다른 것들을 그다지 큰 의미가 있을까 싶다. 일단 유저를 기준으로 스플릿을 했으니 겹치지 않을 것 같다. 그리고 특정 시험이 어려운지는 해당 시험을 본 것들을 기준으로 판단해야 하니까 당장 사람들이 푸는 것을 보고 판단하는 게 바람직하지 않은가?

왜 처음부터 df를 선언했는데 없다고 뜨는 걸까? 아무튼 아래처럼 하여 예외가 없다는 것을 확인한다. 모든 문항 속 앞 여섯 자리 번호는 시험지 번호를 뜻한다.
우리 팀을 소개합니다
1조 공룡알
레벨 1 기반 팀. 미남 정준환 보유!
사용자의 음악 플레이리스트를 기준으로 새로운 컨텐츠 추천. 영화, 소설, 웹툰 등. 음악의 취향에 유저의 특성이 반영되어 있으니까 그에 맞는 추천해주기.
다른 도메인 정보를 통해 콜드 스타트 해결 가능.
플레이리스트를 설명하는 벡터를 만든다. 추천 컨텐츠 벡터를 만든다. 이 상호작용을 구한다.
2조 MLOops
동영이네!
다들 MLOps에 관심을 가지고 있음. 1일 1커밋 목표. 매일 질문 하나씩 가져오기.
카드추천서비스. MLops를 살리는 방향으로 나아가고 싶다.
금융 상품 확장 가능. 고객 생활패턴과 선호도를 통해 추천 진행. 카드 선택 시간 최소화를 꾀할 수 있고, 포인트 적립을 극대화!
3조 Five Guys
선도형네!
수능 문제 추천 프로그램(이제 보니 DKT 같다).
4조 RecCar
성재형네! 6명 팀!
음악 추천 시스템. 스포티파이, 멜론 등의 데이터셋을 활용할 예정.
5조 외않돼조
진명님네!
end-to-end. 집꾸미기에 필요한 물품 추천. 오늘의 집 데이터, 상품 데이터를 통해 추천 진행하기.
6조 RecommendU
민주님네!
자기소개서 추천.
7조 나는 7ㅏ수조
현욱형네!
음악 관련 주제. 새로운 피쳐를 만들어내는 것이 목표
무성 음악의 추천 질이 떨어지고 비주류 음원 개선이 필요함.
사용자의 기분과 상황을 고려한 추천.
melspectogram
미니 세미나 진행
8조 ITS
처음 조 그대로 진행!
전체적인 스타트업 플로우 경험
9조 좋아요구독추천AI
이커머스, 문화컨텐츠 추천! 기업의 BM에 초점을 맞춰서 프로젝트를 진행할 예정
10조 추천해조
6명 팀!
블로그 기반 공간 추천. 특정 카테고리, 추상적 단어로 장소를 찾을 수 있게.
11조 mkdir
우리 팀! 이상의 자세한 설명은 생략한다..
성훈이 형이 재치있게 잘 발표해준 것 같다!
12조 Recommendation is all you need
사용성 있는 프로젝트, 수익 내는 것까지 목표!
여행과 음식을 고려한 추천 시스템. 음식에 어울리는 술, 지역 특색에 맞는 주류
13조 부스트버디
도연이네! 기존 팀 그대로.
논문 추천 시스템. arxiv에서 크롤링하여 유사도 계산 후 논문 추천 계획.
기왕이면 다른 팀들한테도 관심을 많이 가지고 주목하고 싶다. 나름 내가 기억할 수 있는 방향으로 정리를 해봤는데 한번 기대해보자고!
다시 스페셜 미션 1
같은 시험인데 한 명은 15문제 풀고 다른 사람은 5문제 풀었다면, 그 사람은 시험을 포기한 것이 아닐까? 그렇다면 이후 문제들은 0점 처리하는 것이 좋을지도 모르겠다.
판다스의 좋은 분석 도구 groupby! 나는 저번 대회에서 한번도 쓴 적이 없다. Python Pandas 데이터 분석 groupby 사용 방법 예제 (tistory.com) 이걸 많이 참조하면 좋을 듯하다. 대충 각 고유값별 갯수를 알고 싶을 때는 항상 value_count를 활용했는데

이런 식으로 groupby를 써서 나타내는 것도 가능하다. 기본적으로는 index를 기준으로 정렬된다.

유저 id에 count와 평균을 적용한 모습. count는 value_count를 한 값과 같다.
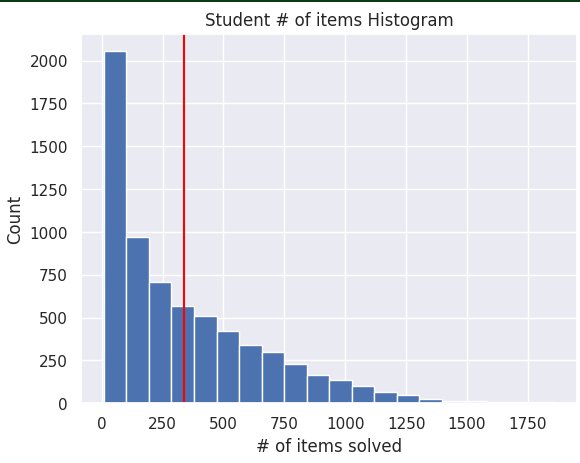
보아하니 문제를 적게 푼 친구도 있고 많이 푼 친구도 있다. 평균 338개 정도의 문제를 유저들이 풀었다. 최대 1860개의 문제는.. 뭐 문제벌레냐. 저번에도 책 5000개 읽은 놈이 있더니만 꼭 이런 놈들이 껴있네..
유저 4명 중 1명은 대체로 100문제 이하로 풀었다.

이것은 학생들의 정답률. 대체로 62퍼의 정답률을 가진 친구들이 700명이 넘어간다. 고른 분포를 가지고 있다고 생각한다.

이건 문항 별 정답률을 나타낸다. 아마 정답률이 낮은 문제가 적은데, 난이도가 어려울 것으로 생각된다.

이건 시험지 별 정답률이다. 문항보다 더 고르게 나타나고 있는데, 보통 시험에서는 문제 난이도를 많이 섞어서 출제하기 때문에 그런 것은 아닐까?
그나저나 groupby가 정말 좋은 분석 도구란 것은 알 것 같다. 이거 조금 더 파는 시간이 필요할 것 같다. 오늘 하루에 될 만한 수준이 아닌 것 같은 걸.

흠. 이것은 문제를 푼 갯수로 나눠서 볼 때의 학생들의 정답률이다. 대체로 많이 풀수록, 정답률은 우상향이다. lmplot 자체적으로 저 직선도 그려주는 모양이다.

피어슨 상관계수. 음의 상관관계거나, 양의 상관관계거나 독립이거나. 1에 가까울수록 양! 아무래도 정답률과 문제 갯수가 크게 상관있는 것으로 확인되지는 않는 듯하다.

그러나 평균을 기준으로 많이 푼 사람이 상대적으로 문제를 더 잘 푸는 것 같기도 하다. 0.16이면 충분히 의미있는 정도의 수치인 것일까? 굳이 전처리를 하거나 고려해야 하는 영역인 것일까?

풀릿 횟수에 따른 태그 간 정답률 비교. 확실히 많이 풀릴수록 정답률이 높다. 무슨 뜻일까? 쉬운 문제를 많이 풀었다?

아까보다 훨씬 상관계수가 높다.
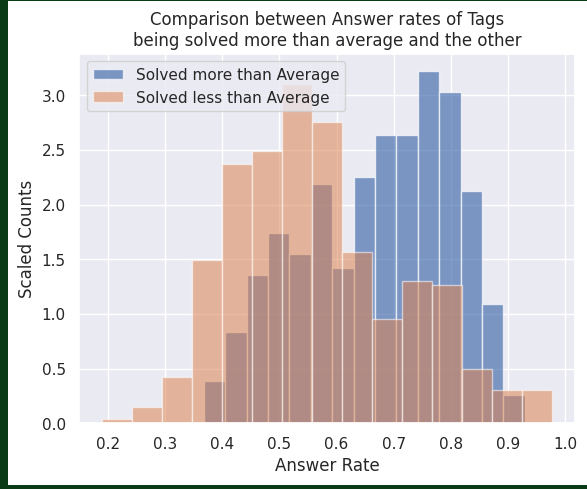
심지어 꽤나 차이가 보이는 것이 확인된다. 평균보다 더 많이 풀린 태그일수록 정답률이 높다. 태그는 확실하게 유의미한 피쳐인 것을 확인할 수 있는 것 같다. 피쳐 수를 줄이더라도 태그는 줄이지 않는 것이 좋겠다는 판단을 내려도 괜찮겠지?
피어세션
오늘은 깃헙 정리를 해보자.

먼저 간단하게 차이를 인식해보자. 우리는 .gitignore가 필요하기 때문에 절대 git add *는 사용하면 안 된다.

브랜치 이름 바꾸기

원격 저장소와 연결 끊기. 새롭게 연결을 할 수 있게 해준다.

성공적으로 우리의 깃이 완성되었다! .gitignore에 올리면 안될 파일들도 제대로 담아줬다.
이제 브랜치를 파서 풀리퀘하기. 할 때는 이슈 번호가 있을 때 꼭 이슈 번호를 명시해주자. 그래야 어떤 이슈와 연관되는지 파악하기 쉽다.
푸쉬를 할 때는 반드시 브랜치를 파서 나중에 풀리퀘를 하는 방식으로 진행하라. 노션에 컨벤션이 있으니 이것을 잘 참고하라.
lgmb(미션2)에서는 제대로 0~1이 나온다. 그러나 왜 베이스라인 코드 모델들은 죄다 -1이냐! 이거 고민해보자
AUC는 0.5를 threshold(분류 임계값) 기준으로 크고 작은 것을 나눈다. 그러니 0보다 작은 값, 1보다 큰 값은 상관이 없이 알아서 정답, 오답으로 낸다. 아무래도 문제는 존재하지 않을 것.
마스터클래스
DKT에 대한 이해, 그리고 추천시스템의 관점에서 접근하기.
대회 중에 꼭 GNN을 활용해보라.

실험으로 나온 팁. 항상 최고인 모델은 없으니 다양하게 실험해봐야만 한다.
AUC만 보는 것이 맞는가? 평가지표를 다양하게 고려해볼 필요가 있다. 더 좋은 metric이 있을 수 있고, auc가 가장 좋더라도 다른 것도 고려해주는 것이 좋다. 물론 데이터 분포와 관계 없이 성능을 알려주는 지표는 auc가 맞다.
모델이 어느 정도 정해지면, 최적의 성능을 위해 튜닝을 해야 한다.
입력 데이터를 임베딩할지, 원핫을 할지, 이것도 의미가 있다.
최대 길이를 어떻게 따질까? 문제를 너무 길게 푼 학생. 최대횟수 넘으면 버릴 수도, 나눌 수도(한 시험의 문항 갯수가 정해져있을 텐데 그것을 기준으로 해야하지 않을까?).
시간을 반영하라. 마지막 문제 푼 시간, 문제 넘어가는 시간.
어떤 학생이 이전에 틀린 문제를 추가로 노력하지 않는다면, 또 틀릴 것이다. 그러나 막상 모델로 보자면 맞춘다. 즉 틀릴 때마다 조금씩 예측 정답률이 오르도록 모델이 답을 내놓더라는 것.
질문 임베딩. 태그의 관계.
추천에서 강화학습 활용하기도 한다. 이는 장기적인 리워드에 대한 고려를 할 수 있기 때문. dkt에 있어서는 그런 것이 더 어울리기도 한다.
여기에서 우리가 한 것은 다음번 이 친구가 맞출 수 있는 정답을 추천해줄 수 있는 방향, 아니면 많이 틀렸던 태그의 문제를 추천하는 것.
아무튼 전형적인 추천과는 조금 다르다고 할 수 있겠다.
추천 시스템에서 앙상블은 쓰이기는 하나, 항상 유지보수가 필요하기 때문에 많이 쓰이지는 않는다.
팀 회의
5강 임베딩은 어떻게 했는가? 범주형 변수들을 임베딩을 하는 방법.
전체 임베딩이되도록 앞 코드가 수정되어야 함. 원래 모델에서.
분업하자. 한명이 앞 모델이 괜찮게 되도록 만들자.
각자 새로운 전처리한 csv를 저장할 수 있는 파일을 만들기.
중기 플랜. 트랜스포머 강의 듣기.
미션 4까지는 최대한 다 하라.

남은 기회 남기기 아까워서 아무 모델이나 돌려보는 중. bert에서 배치를 얼마나 늘릴 수 있는지, 정말 학습률이 너무 높았던 것인지 확인해보고자 한다.

근데 너무 늦게 시도해서 결국 하루가 지나버렸다.. 아쉽지만 어쩔 수 없지. 아무튼 학습률을 낮추는 것은 어느 정도 효과를 보인 것 같다. 배치사이즈의 효과는 아니라고 생각한다. 하지만 모델의 수렴 속도가 빨라진 것이지 학습률 자체를 통해 어떤 유의미한 성과를 내고 있는 것으로도 생각되지 않는다.
회고 및 다짐
공부를 많이 못할 것이라고 생각은 했지만, 정말 미션 1을 다 끝내지도 못했다. 사실 나와 있는 정보만 그대로 따라가면 된다지만 역시 직접 무엇을 해야할지 생각을 하면서, 또 좋은 시각화나 판다스 이용법을 찾아가면서 하니 시간이 빨리 흘렀다. 저번 프로젝트에서 내가 한 수준은 정말 발톱의 때에 불과한 수준이었다는 것을 새삼 느꼈다. 그러니 이렇게 시간이 많이 걸리지.. 하지만 EDA가 여기에 있어도 이후에 관련한 부분들이 계속 나오기 때문에 여기에서 너무 시간을 쏟는 것도 그다지 좋지 않다. 다시 빨리 빨리 나아가보자.
팀원들의 인사이트가 정말 탁월하다는 것을 많이 느끼고 있다. 나같은 나부랭이가 낄 자리가 아니었던 것 같은.. 지로보 센세 ㅠ 하지만 누가 되지 않도록 최선을 다할 것이다. 그래도 안 된다면 어쩔 수 없는 거지만, 안 될 리 없다고 생각한다. 나는 어떻게든 도움이 될 것이다. 열정, 노력으로 조금이라도 기여하고 싶다.
삶의지도를 다 썼는데 적으면서 계속 옛 생각이 났다. 안 그래도 오늘 부캠 라디오 시간에 쓰고 있었는데 마지막 노래가 나오니까 살짝 눈물이 났다. 내 삶에서 여지없이 방황하던 시기가 가장 암울한 순간이었을 지언정 어떻게 보면 또 조금씩 나를 치유하던 순간이기도 했다. 그 시절에 애써 외면해도 스멀스멀 엄습한 불안과 애매하게 나를 지탱하던 위안, 벗어나기 어려운 두려움을 딛고 한발짝 다시 걸음을 내딛으려할 때 그 노래의 울림이 나를 위로했다. 그래서인지 노래만 들으면 이제는 조건반사마냥 살짝 눈물이 난다.
근데, 울려다 말았다. 울어도 다 끝나고 울어야지. 아직은 감성에 젖어 울 때가 아니다. 그리고 힘들어서 울기에는 아직 나는 힘들지가 않다. 나는 아직 갈 길이 머니까, 조금이라도 뭘 끝내고 울자고. 아무래도 삶의 지도를 쓰면서 너무 회상을 많이 한 모양이다.
내일은 오늘 하려 했던 것들을 기필코 다 끝내고야 만다. 스페셜 미션은 직접 진행해야 하는 것이라 내가 빨리 하고 싶다고 할 수 있는 것은 절대 아니다. 그렇지만 확실하게 하자고 다짐한 것은 또 해야지 않겠냐. 그리고 그에 앞서 베이스라인 구조를 전체적으로 정리하는 시간을 가져야겠다.
아직 우린 주저 앉기에는 할 수 있는 것이 많다. 그러니 너도 울지 마라. 부디 너도 너를 믿고, 너를 응원하는 나를 믿고 힘 내길 바란다.
'일지 > 네부캠 AI 4기(22.09.19~23.02.14)' 카테고리의 다른 글
| 20221118금-dkt5, 술페셜, 미션~4 (2) | 2022.11.18 |
|---|---|
| 20221117목-dkt4, 미션1~3 (5) | 2022.11.18 |
| 20221115화-dkt2, 완강 (2) | 2022.11.16 |
| 2022113일-남은 강의, 밑러닝 (0) | 2022.11.15 |
| 20221114월-타운홀, DKT1 (2) | 2022.11.15 |