데일리 스크럼
오늘은 내가 모더레이터. 오늘 피어세션 때 무엇을 할지에 대한 개괄. 다들 강의를 전부 들었다는 가정 하에, 아이디어 브레인스토밍을 해볼까 한다. 일단 주어진 베이스 코드를 파악하고 이를 통해 우리가 무엇에 집중하는 게 좋은지 이야기를 나눠보자. 내일 본격적으로 EDA를 시작하게 될 텐데, 분업 과정이 필요한지, 한다면 어떻게 하는 게 좋을지도 이야기하면 좋을 것 같다.
전반적으로 오늘까지 강의를 다 듣자는 약속은 이행되고 있다. 그래서 피어세션 때 무엇을 할 것인지에 대해서 간략하게 브리핑하고 짧게 스몰톡 시간을 가졌다.
피어세션
코테
구현 문제. 프로젝트 대비를 위해 구현 실력을 갖추는 게 좋을 것이라 판단했다. 후보 문제를 몇 개 두고 최종적으로 한 문제를 골라두고 링크를 준비해뒀는데, 막상 보니까 이 문제 링크여서 그냥 이 문제를 풀었다. 풀어서 망정이지, 못 풀었으면 또 안타까울 뻔했다.
데이터, 베이스라인 코드에 대해
베이스 코드에서 보여지는 특이점이나 이야기해볼 만한 사항, 분석 요소 토킹.
데이터를 전처리하는 과정조차 이미 구현이 돼있다. 이를 충실하게 따른다면 결국 우리가 할 일은 이미 구현된 함수를 어떻게 쓸지 잘 짜는 일이 될 것이다. 물론 우리가 임의로 조금씩 수정을 해도 상관이 없다. 결국 우리는 잘 만들어진 csv파일을 도출하면 된다. 참고로 함수들이 이미 다 알아서 csv 파일도 만들어주도록 작동한다.
부캠이 우리에게 바라는 것. EDA를 확실하게 해보기. 그래서 어떻게 모델을 만들면 좋을지 구상하는 힘을 기르기. 그리고 모델을 앙상블하는 경험을 해보기. 난 어떻게 앙상블되는 것인지 아직 감이 안 잡혀서 이것을 파보는 것도 충분한 도움이 될 것이다. 앙상블은 거의 필수요소로 보인다. ai스테이지 게시판에 나와있다.
파일의 동작법을 아는가?
게시판에 제시된 힌트들. 학습률을 조정하는 것과 기타 하이퍼 파라미터를 튜닝하는 법. 그런데 이것은 우리가 모델이 돌아가게 하고 나서 건드려보면 좋은 것 같다. 앙상블도 그런 추가적인 느낌으로 던질 것일 수도 있다. 그러나 구현이 돼있는 이상 건드려보고는 싶다.
테스트 데이터를 기존 책, 유저 데이터에 병합해 사용할 수 있다. 이것을 코드로만 구현하면 될 듯하다.
제시된 모델 간략한 설명
각 모델은 완성된 형태로 인자를 받는다. 때문에 받는 인자를 잘 정리해둬야 나중에 활용하기도 편할 것이다.
fm과 ffm은 컨텍스트 기반 추천이다. 기존 cf에서는 상호작용 정보만을 고려하기에 이를 개선하는 모델인 것. 각각의 특징을 고려할 수 있도록.

이렇게 조합을 한다.
FM
원핫 인코딩된 특징을 임베딩해서 희소성 문제를 해소한다. 방식은 유저와 아이템 임베딩을 두고 옆으로 붙이는 방식.

식을 정리하면 마이너스 나오던, 기본과제의 그 식이다.

식의 모양은 이렇게 나온다. 코드로도 구현이 그대로 되어있다.
FFM

범주형 변수를 고려함. 일단 사전에 지정한 특징만 고려되도록 짠다. 안 그러면 너무 경우가 많기 때문.
문득 드는 생각으로 코드 단위로 분해하면서 해당 모델이 어떻게 작동하는지 알아보는 시간 가지면 좋을 듯. 그러나 너무 시간을 투자하면 프로젝트에 그다지 이익이 되지 않을 수도 있다. 우리가 쓰는 모델에 대한 설명력을 키우는 용도.
아래부터는 딥러닝 모델.(그럼 위는 아니었나?하면 신경망 구조를 가진 걸 딥러닝이라 부른다. 퍼셉트론 구조를 가지는가?)
NCF
MLP를 활용한, 딥러닝을 처음으로 추천시스템에 적용한 모델. mf와 mlp를 결합. 근데 일반화한 mf라고, 내적하지 않고 아다마르 곱을 한다. 그렇게 두 값이 나오면 concat하고 마지막으로 층을 한번 더 통과.
WDN
Wide & Deep Network. 추천 시스템에서의 두 가지 도전적인 문제. 암기와 일반화. 밀접한 연관을 가진 유저와 아이템이라면 이를 메모해야함. 그러면서 일반화도 해서 전반적인 추천도 가능하게 해야함. 둘을 잘 신경써야한다.
전자는 콜드스타트에 대한 추천이 힘들고, 후자는 저차원 임베딩이 필요한데 이게 어렵다.

그래서 어떻게 대응하는가? 범주 인코딩 층을 넣는다. 원핫인코딩으로 표현하는데 이를 통해 연관되는 빈도를 학습할 수 있다. 그리고 번주형 변수를 저차원으로 임베딩하여 학습하지 못한 특징의 조합을 일반화시킨다.
코드에 잘 나와있다. 그냥 임베딩 층 만들고, mlp만들고. 둘 더하고 시그모이드 처리.
DCN
Deep & Cross Network. 보통 각종 피쳐를 교차해서 잘 고려하는 게 성능이 좋다. 이전 모델들이 시도한 것도 바로 이것.

각각의 정보보다, 상호작용한 데이터가 더 중요하다. 믹서기를 추천할 것인지 정할 때에 바나나와 요리책이 같이 고려되는 데이터가 유의미하다. 근데 희소할 때 이게 잘 안 된다. 그래서 여기에서는 명시적으로 특징을 교차시킨다.

옆에 크로스 레이어를 통해 한번 다 교차를 시켜보는 것.
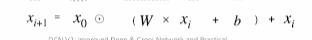
두가지 구조를 가질 수 있다. 교차층을 통해 명시적인 특징 교차를 학습한 후에, 심층을 통해 암묵적인 교차를 학습하는 stacked dcn(직렬). 그리고 교차층과 심층이 각각 학습을 진행하고 나중에 concat하는 parallel dcn(병렬. 왜 이 말을 안 썼을까잉). 데이터에 따라 좋은 성능을 보이는 구조가 다르다. 심층 및 교차 네트워크(DCN) | TensorFlow Recommenders

우리의 베이스라인에는 stacked dcn만 구현되어 있다.
명시적으로 모든 피처를 교차시키다보니 모델이 무겁다. 경량화를 위한 방법. low rank. 행렬 분해를 통해 차원을 줄인다. 그리고 moe. bootstrap같은 방식.
결과적으로 특징 간 상호작용이 강한 정도를 파악할 수 있게 된다.
상호작용을 파악하는데 용이하다면, 이걸로 EDA를 하는 것도 가능하다는 것일까?
이것을 기본적으로 해서 특징 간 상호작용을 파악하고, 그 후에 어떤 모델을 쓸지 정해야 하는 것인가?
여기까지가 우리가 베이스로 활용할 만한 모델이라 할 수 있을 것 같다. 이외에 이미지와 텍스트에 관련된 모델 두 가지가 추가적으로 제시되고 있다.
CNN_FM
말그래도 CNN의 합성곱 연산을 한 후에 FM을 진행하는 모델. 학습할 데이터는 이미 주어진 이미지 파일이라 세세한 형태가 이미 다 지정되어 있다.
코드만 봐서는 정확하게 어떻게 작동하는지 내 눈으로 쫓아가기 힘들다.
Deep_CoNN
텍스트를 다루는 모델이라고 소개되어 있는데 코드로 보면 합성곱 연산을 한다. 합성곱 연산을 유저와 아이템에 대해 한 후에 concat을 하고 FM을 진행한다.
BERT를 사전학습한 모델을 불러온다고 했는데 이는 데이터를 토크나이징할 때를 이야기하는 듯하다.
이 두 모델은 모델 파일을 아예 따로 만들어내는 듯하다. 모델 디렉에 pt파일로 모델 자체를 저장한다.
생각할 만한 요소
콜드 스타트의 문제가 있는가? 우리가 사용하는 데이터는 이미 train과 test가 나뉘어져 있다. 문득 생각하기로, 여태 빌린 적이 없는 사람이나 빌려진 적이 없는 책이 테스트셋에 들어있다면, 즉 콜드 스타트에 해당하는 케이스가 있다면 어떻게 해결할 것인지에 대해 의문이 생겼다. 어제 문의해본 바 이것을 확인하기 위해서 테스트셋을 EDA해보는 것은 치팅에 해당하지 않는다는 답변이 들어왔다. 아직 본격적으로 EDA는 해보지 않았지만, 이런 것을 고려하면서 하면 좋을 것이다.
완전한 콜드 스타트의 경우 데이터가 없기 때문에 인기도, 컨텐츠 기반의 추천을 하는 것이 최선이 될 것이다. 앙상블을 할 수 있도록 모델이 주어졌다. 이런 유저들을 따로 처리하는 과정을 구현할 수 있으면 좋을 것 같다.
분업 요소가 있는가? 한다면 베이스 코드를 본격적으로 뜯어볼 사람과 EDA를 할 사람 같은 식의 분업도 가능은 할 것 같다. 다만 그런 것을 소통을 통해 충분하게 이해를 공유하는 시간을 가져야 할 것이다.
그것이 아니라면 다같이 하나씩 파고들어가는 것도 가능하겠는데, 선택은 자유.
우리는 미니 배치를 만들어 학습을 진행해야 한다. 조금 더 세부적인 과정을 그릴 수 있는가? 전체 파일의 동작 과정을 조금 알고 싶은데 잘 파악이 안 된다.
실제 진행
... 등등의 많은 고민들을 하고 피어세션 때 전부 이야기하려 했으나, 베이스라인 코드와 데이터를 일일히 뜯어본 사람이 나와 희원님 뿐이라 당장 추가적인 이야기를 진행하는데에는 애매한 감이 없잖아 있었다. 결국 이런 쪽으로는 더 이야기하지는 않았다. 다만 나도 잘 이해가 안 된다며 제대로 보지 않았던 메인 파일에 인자를 주는 방법을 희원님이 공유해주신 덕에 현재 프로젝트에서 의도하고 있는 방향이 조금 더 명확해진 듯하다. 근데 이리보니 여태 내가 준비하고 고민했던 것들이 살짝 쓸모 없다는 느낌을 받았다. 전체적인 파악을 못해서 오히려 혼자 너무 돌아가고 있었던 것 같기도.. 아무튼 이미 구현된 모든 모델과 관련한 간단한 명령어를 주는 것만으로도 쉽게 학습을 진행시킬 수 있다.
프로젝트를 진행하면서 부캠에서 우리에게 바라는 것, 그리고 우리가 갖추면 좋을 역량은 일단 무엇보다 앙상블이나 모델을 사용해보는 것. 그리고 하이퍼 파라미터 튜닝 정도가 될 것이다. 여기에 동작 원리나 코드 단위 이해를 통해 설명력을 갖출 수 있으면 더 좋을 것으로 생각된다. 충분한 이해와 구현 실력이 뒷받침된다면 제공된 파일들을 수정하여 모델의 성능을 더 개선하는 것도 가능할 것으로 생각된다.
복기님의 제시로 당장 우리가 무엇을 해야 좋을지 이야기됐다. 일단 제공된 전처리 코드를 세세히 뜯어보면서 모델이 데이터를 어떻게 다루게 되는 건지 파악하는 것. 마침 파일이 4개였고, 여기에 앙상블 파일까지 추가해서 각자 한 파일씩 맡아 내일 피어세션 전까지 확실하게 정리해오기.
용: text_data
민: context_data
고: image_data
희: ensembles
건: dl_data
추가적으로 시간이 남는 인원은 데이터를 조금이라도 더 파헤치면서 EDA 진행하기.
프리톡
건: 알고리즘 먼데이 챌린지. 문제가 암만 봐도 이상한 것들이 많다. 저번주 문제도 뭔가 문제가 있었다. 그래서 그냥 어려우면 이제 그냥 제끼면서 하려고 한다.
고: 알고리즘 먼데이 문제 별로다. 지난 주말 식단 조절을 하지 않고 치팅을 연속으로 했다. 샤브샤브를 혼자 헤먹었다!
용: 다음달 수영 티켓팅 실패...
공부
어제 강의를 다 들었기에 오늘은 본격적으로 스페셜 미션의 내용을 수행하여 EDA를 하는 과정을 익혔다. 그러나 판다스를 사용하는 게 역시 익숙하지 않고, 데이터 시각화 강의의 내용을 다 흡수하지 못해 원활하게 진행하기는 힘들었기에 숙련도를 올린다는 기분으로 코드를 일일히 쳐가면서 연습했다. 또한 피어세션에서 이야기할 것들을 정리하기 위해 각 프로젝트에 준비된 모델들이 어떻게 이뤄져 있고 작동하는지 세세히 알아보았다. 충분히 설명을 할 수 있을 만큼 이해한 것 같지는 않은데, 계속 보면서 익숙해져야할 것 같다.
피어세션 이후에는 어떻게 모델들을 이용하는지 알았기 때문에 일일히 다 학습시켜보고, 앙상블하는 방법을 익혔다. 막상 사용법을 알게 되니 내가 생각했던 것보다 할 게 없어서 조금 허무해졌다. 한편으로는 다른 생각도 드는 것이, 하이퍼파라미터를 조작하는 게 무던히 시간이 오래 걸리는 것이거나, 정말 좋은 모델은 따로 있어서 직접 구현을 하는 과정을 거쳐야 한다던가. 다 된 밥에 숟가락만 올리는 프로젝트에 2주라는 시간이 주어져있는 이유. 아니면 그냥 튜토리얼 격으로 코드를 어떻게 구현하는지만 맛보라는 것 뿐인가?
공부 방향을 어떻게 잡아야 할 지 아직 완벽하게 내 속에서 결론이 나지 않았다.
그래서 내일까지 하기로 한 것을 정리하고, 하고 있던 EDA에 시간을 더 쏟았다.
추가적으로 본격적으로 협업을 위한 깃 사용을 위해 깃을 클론하고 내 브랜치를 만들었다.
이게 깃헙에서 브랜치를 만들고 바로바로 그 브랜치에만 푸쉬하도록 할 수 있을 것이라 생각했는데, 그게 생각보다 쉽지가 않았다..

귀찮게 적어야 되더라고.. 고민하다가 특강에서 풀리퀘할 때 그냥 내 로컬에서 브랜치를 푸쉬하면서 브랜치가 생겼던 것이 기억나 로컬에서도 똑같은 이름으로 브랜치를 만들고 set하니까 작동이 잘 됐다. 아직 깃에 완벽히 익숙하지는 않지만, 적당히 사용하는 법을 익힌 것 같아 다행이다.

혹시나 하여 다른 도메인 대회들을 훑어봤는데, 역시 게시판이 다 다르고 조교가 달라서 써져 있는 글도 달랐다. 그중 CV에 있는 글. 아마 다른 도메인들도 대회 방식은 다 비슷할 것이라 생각된다. 여기에 부캠의 핵심적인 의도가 담겨져있는 듯하다. 결국 우리가 일일히 만져보고, 여력이 되면 새로운 모델도 넣어보고! 익숙해지는 시간을 들이라는 것.
회고 및 다짐
일단 가족과 이야기를 나누면서 나는 당장의 학업에 집중하라는 이야기를 들었다. 내 입장이 충분히 전달되었는지 잘 모르겠지만, 차라리 이레 못을 박아두니 되려 맘이 편하다. 홀로 맘에 짐을 졌던 입장에서 그저 내 일에 집중하라는 시그널을 받은 것 같아서 이제는 정말 더 이상의 신경을 쓰지 않으려고 한다. 천상 머리가 나빠 두 가지 일에 신경을 잘 못 쓰는데 차라리 마음이 편하다. 당장의 거주지 문제는 일단 해결됐을지도.
레벨 2에서 함께 하게 될 팀과 이야기를 나눴다. 당장 소통이 없어 답답하던 차에 한번 토의를 하니 마음이 오히려 홀가분해졌다. 다들 무언가 더 헤쳐나가고자 하는 인상을 받았기 때문이다. 어떤 일이든, 문제를 제기하고자 하는 사람이 없으면 문제는 발생하지 않는다. 그러려니 하는 사람과 그럴 수도 있겠구나 싶은 사람, 그럴 수도 있구나 하는 사람들의 모임에서는 문제 제기를 통한 발상의 전환은 나오지 않는다. 오히려 조금 더 불편한 마음을 가져서 한번이라도 이야기를 해보는 사람들이 있기에 그 사회는 더 발전하고 다양한 방향으로 발산할 수 있다고 생각한다. 그래서 화두를 던진 분께 새삼 고마움을 느꼈다. 가족과의 일 때문에 술을 한 잔 걸친 상태에서 이야기를 나누며 다른 분들이 적극적인 참여를 하는 모습을 보는데 이 팀은 나쁘지 않을 것이라는 생각이 들었다.
생각의 나래가 또 끝도 없이 풀어지니 이제는 그만. 당장의 팀과 약속한 것들을 이행해야 한다. 그것이 나의 성장과 직결될 것이라는 강한 믿음을 가지고 당장 내가 할 일에 집중해야 한다. 아직 완벽하게 내 파트에 대한 설명이 끝나지도 않았고, EDA도 완벽하게 수행하지 못 했다. 내일은 이 부분에 초점을 맞춰 진행할 것이다. 먼저 파일을 뜯어보고 충분한 설명력을 갖춘 뒤에 조금 더 자세한 EDA를 할 생각이다. 하면서 pandas와 더 친해지고 시각화를 하는 연습을 할 수 있었으면 좋겠다.
'일지 > 네부캠 AI 4기(22.09.19~23.02.14)' 카테고리의 다른 글
| 20221027목-4th day of Pstage (2) | 2022.10.27 |
|---|---|
| 20221026 (2) | 2022.10.26 |
| 20221024 (2) | 2022.10.24 |
| 20221023 (0) | 2022.10.23 |
| 20221022 (0) | 2022.10.23 |