Pytorch Basics
이제 기초 문법으로 가보자. 파이토치를 쓰기 위해서는 당연히 사용되는 표현과 문법에 익숙해져야만 한다.
numpy 관련
넘파이의 많은 연산들이 지원된다. 애초에 모든 파이썬의 수학적 연산은 넘파이를 기반에 두니 이런 기능 지원도 어느 정도 당연하다 할 수 있다.(이건 텐플도 마찬가지)
한가지, 넘파이에서는 ndarray가 기본적이지만 파이토치는 tensor를 쓴다.
import numpy as np
import torch
lst = [i for i in range(10)]
nplst = np.arange(10)
t_arr1 = torch.FloatTensor(lst)
t_arr2 = torch.FloatTensor(nplst)
print(t_arr1, t_arr2)
t_arr5 = torch.tensor(lst)
t_arr6= torch.tensor(nplst)
print(t_arr5, t_arr6)
t_arr8 = torch.from_numpy(nplst)보다시피, 넘파이 객체나 일반적인 리스트를 텐서 객체로 바꿀 수 있다. 이와 관련된 여타의 메소드들이 많다. 그냥 대충 tensor를 이용한다 정도만 기억해주면 될 것 같다.
또한 넘파이에서의 ndim, shape를 완전히 똑같이 사용할 수 있다.
그냥 넘파이랑 다 똑같은데, 그러면 왜 텐서를 따로 만들었냐? 텐서 객체는 gpu연산이 지원되도록 만들어져 있기 때문이다.

이밖에도 다양한 넘파이의 함수들과, 넘파이와 연관된 함수들이 존재한다.
참고로 like함수는 많이 쓰인다.
device
device라는 속성이 있다. 이것은 해당 객체가 gpu or cpu에 올라가 있는지 여부를 알려준다.


위의 과정을 통해 어느 메모리를 사용할 것인지를 정해줄 수 있으니 참고하자.
코랩에서 진행하고 있는데, gpu로 하겠다는 일련의 설정이 필요하다.
view, squeeze, unsqueeze
view: reshape와 동일하다. 그러나 메모리를 통째로 가져온다.

보다시피 똑같이 작동한다. 다만, reshape로 변수 할당을 하면 해당 객체는 이전 객체에서 완전히 copy된 객체가 되고, view를 사용하면 메모리를 공유하는 객체가 된다. 즉 이런 상황이 나온다.

분명 바꾼 건 a인데, b의 값도 바뀌어 있는 것을 확인할 수 있다. 보통 view를 많이 추천한다!
squeeze, unsqueeze도 쓸 수 있다. 원래 넘파이에서는 크기가 1인 axis를 전부 없애는 함수였는데, 여기에서도 마찬가지이다. 또한 axis를 지정해서 원하는 곳만 squeeze하거나 unsqueeze하는 것도 가능하다.

연산
덧셈, 뺄셈, 스칼라셈 등등 넘파이에서 쓰던 것들은 대충 다 가능하다.
그런데 한가지 차이가 있는데, 벡터의 내적과 행렬의 내적 연산이 다르다는 것.
벡터간의 내적은 똑같이 dot인데, 행렬간의 내적이면 mm을 써야 한다.
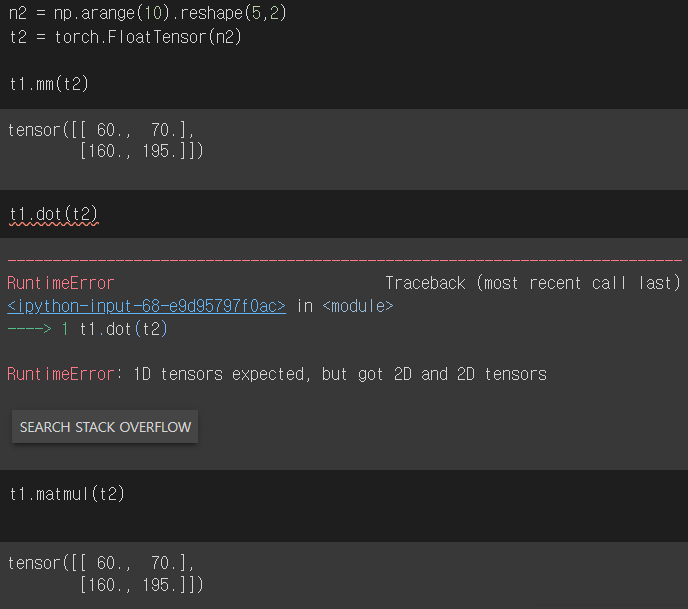
여기에서 세가지 연산이 등장한다. dot은 위에서 말했듯이 벡터 간의 내적을 구할 때만 쓸 수 있다. mm은 오직 행렬 연산만을 지원한다. (서로 호환이 절대 안된다)
mm은 matmul의 줄임말이라 별 다를 게 없어보이지만, 실제 적용할 때 각각의 연산은 조금 다르게 작동한다. 바로 matmul은 브로드캐스팅을 지원한다는 것. 그래서 그런지 matmul은 벡터 연산도 된다.

보다시피 아래 matmul은 알아서 브로드캐스팅이 일어나서 뚝딱 계산을 해버렸다. 이런 특성 때문에 내 실수로 원치 않는 결과를 잡지 못할 수도 있으니 mm을 쓰는 것이 권장된다.

참고로 mm으로 일일히 브로드캐스팅을 직접 구현해줘도 된다. a[0]이니 [2,3]의 행렬을 b와 행렬곱하는 상황이다. 근데 b가 벡터였기 때문에 임의로 늘려서 연산을 하고, 다시 unsqueeze를 하는 모습이다. 실제로 이렇게 하는 경우도 있다고 한다.
nn.functional
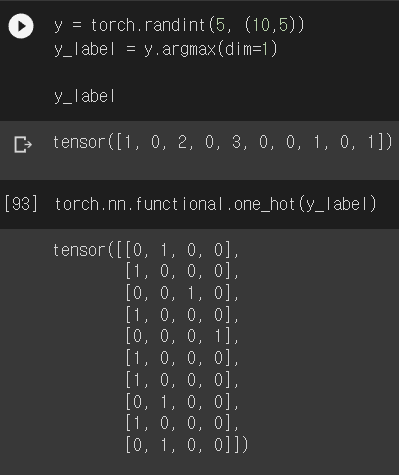
이 모듈 안에 우리가 쓰게 될 많은 함수들이 또 있다. softmax, one-hot encoding 등등.
여기에 많긴 한데, 다 말할 수는 없고, 모듈 안에 있다는 것만 알고 나중에 찾아가면서 활용하는 것이 좋다.

AutoGrad
넘파이 관련은 이정도! 이제 자동미분으로 들어가보자.

이런 식으로 한다~ 방식을 잘 알아두자. requires_grad를 넣으면 이 놈이 미분에 쓰일 놈이라는 것을 명시해주는 것이다.
위 상황에서 w를 미지수로 두고 미분하면 $20 \times w$가 될 것이고 이때 2를 넣으니 40이 나오게 된다.
참고로 이렇게 쓸 일은 보통 없다. 우리는 데이터를 사용하게 될 텐데, 대부분의 데이터는 이미 requires_grad가 True가 되어 있다고 한다.
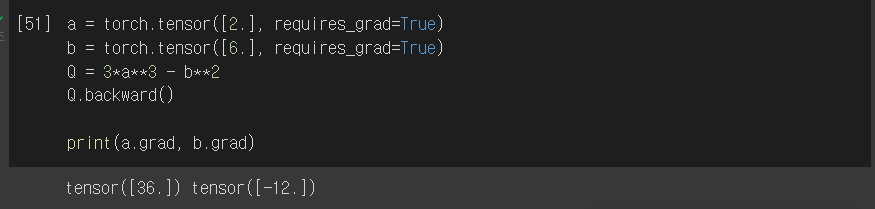
보다시피 편미분도 간단하게 지원된다.
만약 미분을 하고자 하는 값이 한 개가 아니라면? 그럴 경우에는 우리가 몇가지를 미분하는지를 backward에 인자로 전달해주어야만 한다.

external_grad를 통해서 미분하려는 객체의 모양을 미리 알려주었다. 우리가 위에서 배운 넘파이의 like 함수를 사용해도 가능하다.
external_grad = torch.ones_like(a)어렵지 않다! 참고로 해당 배열에 1이 아니라 다른 값이 들어가면 미분을 진행한 후에 해당 값을 곱해준다. 1을 넣으면 곱셈에 대한 항등원이기에 그냥 미분값이 나오는 원리이다.