20230116월-최종 6
diversity중, rating 지표에 대하여
행렬의 맛을 알아버린 후, 행렬로 미리 만들어서 계산을 빠르게 하는 것에 관심이 많아졌다. 그래서 이제는 상준이가 하고 있던 다양성에 대해서도 조금은 파보려고 한다. 시간 단축이 절실하니까. 그런데 rating 지표는

식이 이렇게 생겼는데, 이때의 U는 두 아이템에 상호작용한 유저만을 이야기한다. 사실 분자는 행렬곱 때 문제가 발생하지 않는다. 그러나 분모가 문제다. 분모를 행렬곱으로 구해낼 방법이 떠오르지 않는다. 한 행을 다 쓰는 것이 아니다 보니 결국 i와 j가 상호작용하는 구조를 가지게 되고, 이 말은 결국 각 i와 j의 쌍을 모두 고려해야한다는 말이 된다. 미리 행렬을 만들어두면 분명 재정렬을 할 때 편리하지만, 그 행렬을 만드는 것 자체가 복잡한 일이 되어버린다는 것이다.
오전 내내 이 고민이었는데 명쾌한 답은 나오지 않았다. 다만, 한 가지의 돌파구가 있을 것 같기도 하다.어차피 다양성은 한 추천리스트 안에서 생기는 쌍만을 고려하면 된다. 아이템 i와 j는 결국 100개 중에 있다는 것이고 그 쌍만 고려하면 된다는 것이다. 그렇다면 내가 어제 serendipity를 짤 때 두번째로 고안한 방법을 적용시킬 수 있다는 것이다. 10분 정도 걸렸던 그 알고리즘.
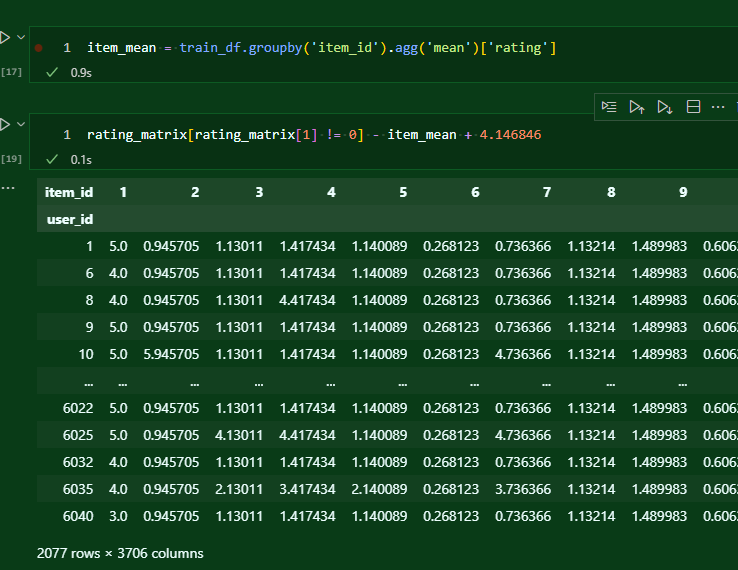
상준이가 만든 코드의 도움을 받아 각 아이템의 평균은 쉽게 구할 수 있었다. 그냥 mean을 때려버리면 결측에 해당하는 값도 고려가 되지만, 신기하게 위와 같이 코드를 짜면 결측값은 고려하지 않고 순수하게 평균을 구해준다. 아래 데이터프레임은 아이템 1번의 평균값을 다시 더해서 열 단위로 삘셈이 들어간 것인지 확인한 것.

음. 일단 내가 의도한 것처럼 동작을 하지 않았다. 그런데 그것보다 큰 문제는 시간이 너무 걸린다는 것이다. 한 유저의 추천리스트에 대해 3분이면 처참한 속도라 하겠다. 전체 유저에게 추천된 고유한 아이템의 갯수는 2400개 가량. 이걸 또 일일히 쌍을 잰다면 재정렬 이전의 행렬을 만들어둘 수 있을 것이다. 그러나 그걸 만드는데 걸리는 시간이 정말 어무막지할 것이다.

조금 더 식을 수정했더니, 얼추 내가 원하는 값이 나오고 있다. 시간도 단축됐지만, 그래도 1분이 걸린다. 유저당 1분이면 처참하다.

이 작업이 오래 걸린다.

컬럼의 갯수를 줄인다면 속도는 당연히 빨라진다. 유저당 8초.

사실 이거면 내가 원하는 아이디어를 실행할 수 있다. 할 수는 있는데.. 100개에서의 쌍을 뽑아서 계산하는데 걸린 시간이 8초면 만약 전체 아이템에 대해 이걸 한다면? 4000*4000이면 16000000.

한번 시도해봤는데 역시.. 오래 걸린다. 결국 한 행렬을 완성해내면 그건 그 데이터셋에 대해서는 영원히 써먹을 수 있으니까 나쁘지만은 않은 장사이기는 하다. 근데 에러가 어무막지하게 뜬다. 또 다른 방식의 에러가 떴나 했는데 검색한 바로는 결국 또 0으로 나누는 문제라고 하네.
음. 이건 도저히 방법이 없는 것 같다. 차라리 해당 리랭킹을 쓰지 않는 방향으로 가는 게 차라리 나을 것 같다.
피어세션 때 이야기를 들어보니 상준이는 결국 모든 쌍에 대해 행렬 계산을 한 값을 피클로 저장해내는 방식을 선택한 듯하다. 행렬 모양은 아니고 상삼각행렬에 해당하는 부분을 딕셔너리로 만든 듯한데, 다 만드는데 2시간 걸렸다나. 내 코드로 구현할 경우에도 비슷한 정도의 시간이 걸릴 듯하다. 근데 정작 재정렬에 있어서는 30초 정도가 걸렸다고 하는데, 그렇다면 현재 행렬을 사용하는 내 코드보다도 빠르다는 것이 된다. 딕셔너리 형태가 확실히 더 나은 걸까?
일단은 작업 우선순위가 바뀌었다. 나중에 다시 코드를 돌아볼 여유가 생길 것이라 생각하고 당장은 팀 내에서 정한 일을 하자.
사소한 이슈 해결 및 지표 계산 개선

이상하게 특정 파일들이 내 탐색기에서 추적이 안 되는 이슈가 있었다. 간단하게 csv 파일을 저장하거나 그랬는데 그게 탐색기에서 뜨질 않으니 여간 불편한 게 아니었다. 근데 이번에 브랜치를 변경하다가 알게 된 건데 이근호씨가 추적하지 않는 파일들이 탐색기에도 안 뜨도록 설정이 돼있었다. 아마 누나 맥북을 쓰면서 생긴 설정 연동 이슈인 것 같다.
조금 고통 좀 받았는데, 이제는 잘 추적이 돼서 다행이다.

이제 이전에 만들었던 지표들을 개선할 시간이다. 행렬에 일련의 득도?를 해서 그런지 이제는 뭔가 무섭지가 않은 느낌이다.
다시 짜는 것은 그다지 어려운 일이 아니었다. 기존 코드를 그대로 잘 적용만 시키면 된다.

그보다 문제를 발견했다. 지표는 분명 0과 1 사이로 떨어지는 값이 되어야만 한다. 그러나 막상 보니 이상한 값들이 섞여있더라는 것이다.

이렇게 이상한 값이 나올 수 있는 부분은 대각행렬 부분밖에 없다. 그 부분은 어차피 쓰일 일이 없다고 단정짓고 따로 값처리를 하지 않았으니까. 그도 그럴 것이, 아이템 i,j의 거리를 따지는 것이 i행 j열인데 대각행렬은 자기 자신을 본다는 뜻과 같다. 여기에서 j는 유저 프로필 아이템들만 해당되는데, 추천되는 아이템 i는 유저가 본 아이템을 추천하면 안 되니까 i와 j는 겹칠 일이 없어야 마땅하다. 그런데 대각행렬 부분이 계산에 쓰이고 있다면, 이는 중복 추천이 일어나고 있다는 뜻과 같다.
의도한 것은 아닌데, 값이 이상하게 나오는 것이 추천이 이상하게 일어나고 있다는 것을 판별하는 요소도 되어주고 있다.

pmi 행렬의 대각행렬 부분의 정보.


공교롭게도, 정말 이미 본 아이템에 대해 추천이 일어나고 있다. 내가 데이터를 잘못 쓰고 있는 것인가?
하지만 이것은 내 코드가 잘못된 것을 나타내는 것은 아니다. 오히려 내 코드가 중복 추천을 감지하고 있다는 것이라 살짝 좋다고 볼 수도 있을 것 같다. 여튼 내 코드의 문제는 아닌 걸로. 따지자면 지금 대충 만들어진 EASE로 inference한 값을 쓰고 있는데 그때 내가 설정 실수를 한 것이라 보면 될 것 같다.
회고 및 다짐
어렵지 않게 코드는 고쳤으니, 이제는 백엔드 쪽을 나도 같이 팔 차례이다. 이번 주에 fastapi 백엔드를 구성하는 과제도 있었으니 늦지 않게 깊게 공부를 할 필요가 있다.
그리고 승렬이랑 같이 할 작업들이 있었는데, 바로 실제로 어떠한 데이터가 들어오면 그 데이터를 통해서 각종 지표들을 꺼내게 하는 코드를 만드는 것이다. 이것은 여태 만든 코드들이 잘 돌아가는지 체크도 하면서 넘어가야 하는 부분이라 나도 같이 하면 좋겠다 생각하면서 같이 하기로 한 부분. 그 중 serendipity는 잘 나오도록 내가 수정을 해낸 것이다.
이제 나머지 지표들이 잘 나올 수 있도록, 조금 수정하는 과정을 거치는 것을 하면 되는 것이다.