20230104수-movie 18, 최종
아직 영화 추천 대회이지만, 우리 팀은 이제 최종 프로젝트를 준비하기로 마음 먹었으니 확실하게 준비해보자고
XAI
XAI Review - 1. Overview - YouTube 내가 개념을 일단 잘 모르기 때문에 강의 영상을 먼저 보면서 틀을 잡을 필요가 있다.
XAI란

인간의 explanation이 아닌 AI가 explanation을 도출하며, 사람이 AI의 동작과 최종결과를 이해하고 올바르게 해석할 수 있고, 결과물이 생성되는 과정을 설명 가능하도록 해주는 기술!
간단하게는 그냥 설명가능한 AI라고 할 수 있겠다. eXplanable AI!
왜 필요한가?
- 모델을 발전시킬 단서를 포착할 수 있다.
- 설명을 갖추는 것이 바람직한 테스크가 존재한다. 가령 자율주행이나 추천시스템
- 인간이 보지 못하는 인사이트를 발견할 수 있다.
XAI를 통해 투명성, 신뢰성과 공정성을 얻을 수 있다.
분류
대략 3 가지 분류 기준을 두어 XAI를 분류할 수 있다.
scope

범위를 통해 나누는 것.
- local - 한 데이터에 대해서 따지며 나온 결과와 진행사항을 따지는 것이 가능함. 한 유저에 대한 어떠한 결과가 나올 때 설명을 한다던가.
- global - 모델 전체를 단위로 인식하여 전반적인 설명을 할 수 있음.
먼저 local XAI에 대해 보자면,
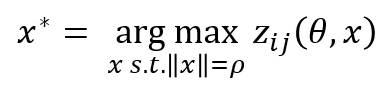
Activation Maximization
이러한 식을 최대화하는 input pattern을 탐지하는 방법이 있다고 한다. 이를 통해 피쳐별 중요도를 찾을 수 있다고..

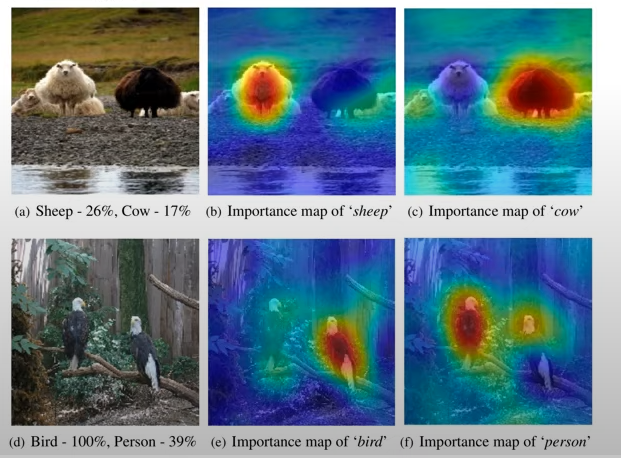
Saliency Map Visualization
output class에 해당하는 미분값을 픽셀별로 계산하여 픽셀 별 중요도를 도출. 그러니까 사진 픽셀은 각각 하나의 텐서이고 모델을 통과시키고 역전파를 하면 각 픽셀에 대한 미분값이 나올 것이다. 이때 미분값의 크기를 보고 영향력 주는 픽셀이라 가정한다.
위 사진은 분류 문제. sheep을 26퍼로 보는데 그때의 미분값, cow일 때의 미분값을 따진다는 듯. 분류 문제면 소맥을 취할 텐데, 이 과정에서의 미분을 각각 나눠서 나아간다는 뜻으로 보인다. 원래 역전파는 그렇게 되지 않는 것으로 아는데.. 역전파가 아니라 단순하게 각 위치에서의 미분을 따지는 것이라면 가능할 것 같기는 하다.

Layer-wise Relevance backPropagation
줄여서 LRP. 결과 예측값에 역전파를 통해 분해하고 입력값의 피쳐의 연관성 점수를 낸다.
위 두번째까지는 흔한 딥러닝에서의 식이다. 그리고 R이라는 연관성 값을 따진다. 이는 역전파를 통해 분해되고, 모든 y에 대해 sum을 해준다고 한다.
뭔 소린지 잘 모르겠다.
이 정도가 local XAI 예시 되시겠다. global XAI는 일단 복잡한 모델을 선형적으로 축소하여 해석하기 쉬운 형태로 만든다. 대체로 rule-based, tree-based 모델에서 활용되는 방식. 비선형 모델을 선형 모델로 대체하여 해석하는 경우도 있다고 한다.

Class Model Visualization
local XAI에 있던 Activation maximization을 global하게 확장.

Concept Activation Vectors
줄여서 CAVs. 사람이 구분할 수 있으면 P, 없으면 N으로 정의한다. 위 사진에서 얼룩말과 그렇지 않은 것을 나눈 것을 확인할 수 있다. 이 그림을 모델에 넣어 이진 분류를 시킨다. 학습을 시킬 때, 이진 분류가 되감에 따라 변화하는 가중치 내지 층의 변화를 평가하는 방법.


이것은 TCAVs, testing with CAVs라는 방법론까지 나아가게 되는데, 정확하게 이해는 못 했다. 요지는 입력값들을 나누는 선이 되어주는 벡터를 찾아내는 것에 있는 것 같다.

Spectral Relevance Analysis
줄여서 SpRAy. 군집화한 후 상관있는 입력값을 도출. local XAI에서 나온 LRP를 활용해 연관성 점수를 내고 이를 통해 클러스터링을 진행한다. 군집은 각 입력값의 eigenvalue(고유값)간의 차이를 통해 찾는다고 한다.
Methodology

메소드로 나눈다. 간단하게 말하자면 역전파 방식의 모델인지 아닌지 역전파를 활용한다면 입력값의 미분값을 활용한다. 그렇지 않다면 입력과 출력의 연관성을 찾는데 주력한다.

Saliency Maps
위에서 봤던 방법. 어떤 것으로 특정값으로 분류됐는지 알고 싶을 때 히트맵을 그리는 것.

Gradiend Class Activation Mapping
줄여서 GradCAM. CNN에서 마지막에 FC 층을 보내는 것이 아니라 Global Average Pooling 층을 건너게 한다. 이를 통해 위치 정보를 보존 이 과정에서 각 층이 어떤 것을 보고 어떤 분류를 해낸건지 알 수 있게 된다.
음. 여태 위에서 본 것 Saliency나 그런 것들이 결국 다 이러한 방법을 쓰는 것 아닌가? 이 놈은 마지막 층을 달리 한다는 점에서 유달리 다른 것이라 일단 받아들이겠다.

Salient Relevance Maps
LRP에서 연관성 점수를 뽑는데 맥락 정보도 활용한다. 각 픽셀별로 값을 내면서 각 픽셀의 정보를 얻는 듯하다. 맥락 정보를 더하기 위해 canny-edge based detector를 sr map에 붙인다는데, 각각이 뭔지를 모르겠다. 이런 게 있다 정도로 넘어가보자.
위에서 본 SpRAy처럼 LRP를 활용한다. 그러나 이 놈은 모델에 대한 설명을 하는 식으로 작동하지는 않는다.

Attribution Maps
입력값이 모델에 가한 기여도는 미분값을 통해 알 수 있다고 가정한다. 그 intergrated gradients가 바로 위의 수식. 입력값과 베이스라인으로 존재하는 x를 상정하는데 이 베이스라인을 어떻게 잡는지가 또 튜닝의 요소이기도 한 모양이다.

도메인 지식을 학습 단계에 추가로 인코딩하여 모델 해석에 기여한다.
데일리 스크럼
어제 밤에 급격하게 피곤하다 싶어서 일찍 잤는데, 늦잠을 자서 결국 지각했다. 목도 잠기고 머리도 지끈거리고 코도 계속 나오는 것이 전형적인 감기 증세.. 정말 억울하게 생겼네. 몸 마음 안정되는 게 하나 없다. 그래도 안 할 순 없다.
나는 계속 시각화할 수 있는 지표들에 대해 알아보는 중
피어세션
shap 라이브러리 설명 찾아보는 중
로그를 씌우는 것. pca하고 하는 것과 아닌 것의 차이.
인기를 기반으로 찍어볼 수도 있는가?
로그 변환 - 음수 값을 넣으면 그값을 무시하고 변환한다.
멘토링
저번 주를 기점으로 사실 멘토링은 끝이었지만, 이번 주도 멘토링 진행하기로 함!
차원 축소의 의미가 없지 않을 수도. 그러나 실제로 그냥 값이 다 비슷한 경우가 있을 수 있다.
유저와 아이템을 같이 보는 것이 중요하다.
유저랑 아이템을 합친 다음에 차원 축소와 시각화를 해보라.
유저 31360 + 아이템 6807 상태에서 해보라는 것. 유저와 아이템의 연관을 파악할 수도 있다.
그리고 유저가 덴스한 게 문제라면, 잘 퍼뜨리는 것도 방법 - > ?
이걸 딥러닝 모델을 통해서 이걸 표현할 수도 있다. 배치 단위로 보여주는 것이 가능하다.
pca를 딥러닝으로!
차원축소는 정사영의 의미를 가진다. 이때 정사영 자체를 학습시킨면 무슨 의미를 가질까?
장르를 통해 유저를 나눌 수도 있다. 스릴러 보는 사람들끼리 엮일 수도 잇따.
근데 장르로 엮이는 것만으로도 어느 정도 의미가 잇을 수 있다. 스릴러라는 장르를 가지고 있는 것만으로 위치가 비슷하다던가.
차원축소 없이 장르로 클러스터링이 되는지? 잘 뭉쳐져 있는지 부터 확인해보는 게 좋다.
장르 간의 상관관계.
shap value를 사용할 수 있는가? xai를 믿지 않는 편...
igmc 깃헙.
bipartite에서 2hop을 하면 아이템 간, 유저간 유사성을 볼 수도 있는 것이다.
그래프를 이용한 시각화. 시리즈물에 유용할 수도 있다.
딥러닝은 층이 다양하다. 이때 그 파라미터를 보기보다, 데이터를 흘려보내서 나온 각 층의 출력값을 벡터로 취급해서 시각화를 해보는 건 해볼 만하다. cnn에서 각 층을 시각화해보듯이. feature extraction으로 검색해보라.
Diversity, Serendipity, Novelty, and Coverage: A Survey and Empirical Analysis of Beyond-Accuracy Objectives in Recommender Systems
다양성, 의외성, 참신성, 포용성(자의적인 번역이다) 추천 시스템의 정확성-너머의 목표에 대한 조사 및 실증 분석
다분히 내가 이해한 것에 맞추어서, 충분히 아는 내용을 생략하면서 번역한다. 구태여 말이 되게 구성하지도 않을 것이다. 내 머릿속에 지표에 대한 틀을 구성하는 것이 우선이기 때문이다.
초록
추천시스템에서는 전통적으로 유저가 실제로 내린 평점에 기반해 정확도라는 지표에 집중했다. 그렇지만 추천이 다양한지, 참신한 아이템이 들어있는지도 추천의 질에 있어 중요한 것으로 점차 자리매김하고 있다. 그래서 정확성-너머(beyond-accuracy)의 지표에 대한 연구가 점차 이뤄지고 있다. 다양성, 의외성, 참신성, 포용성을 알아보자! 여태의 연구는 각 특정 지표에만 초점을 맞추어 각 지표간의 연관성에 대한 연구는 제대로 이뤄지지 않았다. 그러니 이 연구를 빌어 각 지표를 최적화하는 과정에서 다른 지표가 어떻게 변화하는지 볼 것이다. 연구를 통해 다양성은 참신성과 양의 상관관계를 가지고, 참신성이 포용성에 긍정적인 영향을 미친다는 것이 밝혀질 것이다.
개요
이제 추천 시스템의 랭킹 테스크는 정확성만이 아니라 다양함과 참신함을 포섭하고자 하고 있다. top n 추천의 문제에서는 작은 추천 집합을 사용자가 받기 때문에 이러한 품질은 굉장히 중요하다.
diversity. 정확성과의 관계는 정보 검색(Information Retrieval) 분야에서 먼저 연구되었다. 경제학에서는 투자에 대해 위험과 기대 수익을 트레이드 오프 관계로 바라본다. 문어발 치듯이 주식을 다양하게 사면 위험은 줄면서 수익이 줄고, 기대수익을 최대화하는 것은 위험도를 높인다. 추천으로 돌아오자면, 정확성만을 추구하는 추천을 하게 되면 추천되는 아이템들이 서로 너무 유사한 경향이 있어 오히려 사용자를 만족시키지 못하게 될 수도 있다. 반대로 추천을 다양하게 하면 관심 갈 항목의 선택지가 넓어져 이러한 위험이 줄어든다.
serendipity. 찾아보지 않았던 기쁘고 값진 것을 찾는 과정을 말한다. 직접 찾아볼 생각은 안 했는데 막상 추천 받으니 이거 의외로 좋은데? 싶을 때 serendipity 지표를 높게 준다는 것. 번역 그대로 뜻밖의 재미! 의외성은 놀라우면서 관련성이 있어야 한다. 제대로 연구된 적은 없는 듯. 정의하고 측정하기 어려우니까..
novelty. 대충 의외성과 연관이 깊다. 유저에게 알려지지 않은 것을 추천해주는 것. 때로는 의외성을 참신성의 하위 집합으로 보기도 한다. 무슨 말이냐, 유저가 보지 못한 모든 것들이 참신성의 범주에 들어가는데, 그 중에서도 연관성이 있는 것들이 의외성의 범주에 들어간다는 것이다. 누군가는 의외성 대신에 unexpectedness, 예기치 못함을 새로운 지표로 꺼내어 참신성과 확실히 구분하려는 시도도 했다. 아무튼 참신성과 의외성을 구분하는 게 바람직하지 않겠냐, 그래서 참신성은 보통 유저 독립적인 방향으로 정의된다. 인기도의 반대, 인기 없는 것을 추천하는 것을 참신한 것으로 보는 거다! 그래서 개인과는 별개로 지표가 해석이 되는 것이다.
coverage. 이걸 포용성이라 부르는 게 맞을지 모르겠다. 아무튼 이건 추천이 가능한 모든 아이템의 목록을 커버하는지를 보여준다. 포용성은 참신성과 자주 연결되는데, 제대로 연구된 바는 없다.
이러한 지표들은 도메인 마다 유저의 니즈마다 달라질 수 있으니 정성적이라 할 수 있다. 다양한 추천 시나리오에서 각각 다르게 적용될 수도 있고, 바뀔 수도 있고, 가치를 잃을 수도 있다는 것에 유념하자. 상품 추천에서의 이 지표들과 음악 추천에서의 지표는 그 중요성이 다를 수 있다. 이 지표들은 각 유저의 요구나 선호에 맞춰 조정되는 것이 바람직하다.
본 글에서 보일 목표는 두 가지이다. (1) 정확성-너머의 지표에 대한 정의와 최적화 기술에 대한 광범위한 검토를 제공한다. (2) 각 지표 사이의 관계에 대한 중요한 통찰력을 보여주는 실험을 수행한다.
참고로 연구마다 용어가 일관되지 않다. 다양성이 각 유저에게 각각 다르게 아이템을 추천하는 것을 말하기도 하는가 하면, 전체 아이템에 대해서 추천된 정도(포용성과 같은 뜻)를 말하기도 한다.
다양성
위에서 간략하게 봤듯이 정보 검색 연구에서 아이디어가 나왔다. tf-idf처럼, 문서 속 단어들(추천이 정확한지)만 볼 게 아니라 다른 문서들과의 유사성(다양한지)도 봐야한다는 것이다. 만약 유저의 쿼리에 재규어라는 말이 들어간다면, 이것 자체만 봐서는 이것이 동물인지, 차인지, 기타 이름인지 알 수가 없다. 정보 공간의 광범위한 영역이 반영되도록 한다면 사용자의 쿼리를 정확하게 파악하는데 도움이 된다. 그리고 이렇게 광범위하게 보는 게 바로 정보 검색에서의 다양성이다.
추천 시스템에서 다양성이란? 추천해준 리스트가 있을 것이다. 이 리스트 속 아이템들 각각 pair-wise쌍의 거리를 재고 평균을 내는 것이다.

R이 한 추천 리스트. 그 속의 아이템들 간의 거리를 잰다. 두 서메이션이 있다는 게 pair-wise를 뜻한다. 그리고 이를 다 더해서 평균을 낸다. 이런 방식으로 다양성을 재는 건 흔하다고 방식이라고 한다(그래서 러셀이 당연히 알 거라는 식으로 이야기했나). 그런데 여기에서 거리를 재는 방식이 저마다 다르다. 각 아이템이 멀티핫 인코딩 방식으로 표현될 경우(content descriptor가 뜻하는 게 맞나?) 자카드 유사도, 그냥 벡터일 경우에는 코사인 유사도를 쓸 수 있다. 평점 벡터라면 해밍 거리(길이가 같은 벡터에서 얼마나 값을 바꿔야 둘이 같아지는지), 피어슨 계수, 코사인 등으로 할 수 있다.
메모리 cf에서는 이웃을 활용한다. 이 이웃만을 사용하여 거리를 측정할 수도 있다. MF로 치면 잠재 요소 벡터를 통해 할 수도 있을 것이다. - 음. 이건 유효한 아이디어. 우리도 mf를 한다. 여기에서 아이템의 벡터를 꺼낼 수 있고 이를 통해 각 거리를 구할 수 있을 것이다. 근데 사실 corr 쓰면 그걸로 상관관계 이미 구한 것이기도 하다..
그런데 이렇게 한다고 유저한테 다양하게 인식되냐? 뭐 영화 같은 경우라면 장르 같은 걸로 다양성을 정의하는 게 더 낫지 않겠냐? 적용 범위, 중복성, 크기 등의 세 가지 장르 기반 다양성 지표를 꺼낼 수 있다. 추천된 아이템 리스트가 얼마나 장르들을 잘 커버하는지, 중복을 피하는지, 그리고 리스트의 길이에 따라 다르게 커버력과 중복성을 체크해야 하기에 길이도 따져야 한다. 이 비판을 한 사람, vargas는 이상적인 장르 분포는 아이템을 랜덤하게 샘플링할 때 달성된다고 한다. 이 아이디어는 그놈의 정보 검색 분야에서 비례에 의한 다양성 개념과 유사하다. 문서 뭉치에서 주제의 인기도와 각 주제를 커버하는 문서의 갯수가 비례할 때 다양하다고 보는 개념이 있다(뭔 소린지,,,). 그 개념과 유사하다는 것. vargas는 장르 다양성을 측정하기 위해 확률론 모델을 제안한다. binomial diversity. 이항 다양성? 무작위 샘플링을 해서 얻는 분포와 장르에 따른 분포가 유사하면 다양하다고 본다는 것. - 먼소린지 잘 모르겠다만,
다양성을 연관성과 엮어서 탐구하기도 한다. ndcg처럼 일단 순위로 줄 세우고 이미 추천된 아이템과 관련 있는 아이템이 나온다면 지표를 낮게 주는 방식. - 이것도 뭔 소리냐.. 근데 이쪽 문장에서는 관련성이 높으면 penalize한다고 해두고 다른 곳에서는 관련성을 유지하고 높이는 게 좋다고 이야기한다.
아무튼 관련성이 없는 추천은 좋지 않다!
시간이 지남에 따라 동일한 유저에 대해 추천이 어떻게 바뀌는지도 다양성으로 볼 수 있다.
이 외에도 사람마다 다르게 추천을 해주는 것이 다양성이라고도 볼 수 있는데, 이건 본 글에서 다루지 않는다고.
다양성을 높일 때는 관련성을 유지하는 것을 고려하면서 다시 순위를 매기거나, 다양성을 지향하는 새 모델을 짜는 2가지 경우가 있다.
일단 전자를 보자. 순위를 조정하는 다양성 쪽은 C라는 큰 범주의 추천 후보 아이템 군을 두고 거기에서 크기가 N인 추천 아이템 집합 R을 만든다. 이 C는 기존 추천 모델로 만들어지기에 유저 관련성은 보장되는 상태. 이때 C의 아이템 중 목적 함수를 최대화하는 아이템을 R에 계속 넣는 방식. 목적함수는 R에 들어간 아이템과의 연관성을 고려하면서 다양한 아이템을 뽑도록 정의된다.
Maximal Marginal Relevance (MMR)
[1 5 10 37 64]
생기는 의문. 다양성과 포용성은 뭐가 다른 거냐?
회고 및 다짐
정신 차려야지 하는데 이제는 몸이 말썽이다. 아침에는 짜증 났는데, 되려 좋다. 지금 비몽사몽하긴 해도 몸살이 난 건 아니라 얼추 공부를 할 수는 있다보니 억울해서라도 더 공부해야겠다는 일념이 일어난다. 억하심정 공부법.. 그냥 빡시게 공부에 집중하다보면 또 언젠가 무뎌질 일들, 너무 흔들리지 말자. 어차피 사람은 다 떠나간다. 내 마음 속에서 조금 빠르게 보냈을 뿐이다.
정말 화나는 건 그런 혼란 틈새로 아무래도 되지 않겠냐는 식으로, 앞으로 나아가길 멈추는 것이다. 될 대로 되라는 식으로 나를 1년 동안 파괴했던 마음에 다시 먹히면 안 된다. 인생 통틀어 내 의지를 가장 약화시키는 종류의 것이다. 이런 일들 날 때마다 그냥 무너질 수는 없다. 그러니 그냥 해내야 한다. 마침 딱 좋게 새로고침하라고 주어진 시간을 잘 쉰 격이 되었다. 그러니 이제는 다시 돌아가야지!