챕터 3. SQL 기본 문법
3-1. SELECT ~ FROM ~ WHERE
select 문은 만들어진 테이블에서 데이터를 추출하는 기능을 한다. 이는 데이터를 변경시키지 않는다.
select 열 이름 from 테이블 이름 where 조건식

이번 내용을 위해 책에서는 나름의 예제 데이터베이스를 구축하는 코드를 준비해놓았다.
위에서부터 순서대로 코드들을 보면서 얼추 감을 익혀보자. --을 쓰고 띄어쓰기를 하면 주석처리를 할 수 있다.
buy를 만드는 부분에서 auto_increment는 번호를 매기는 코드. 이렇게 해두고 , 나중에 insert할 때는 해당 자리를 null로 넣어주면 된다. 그러면 알아서 번호가 매겨진다.
select select_expr
[from table_references]
[where where_condition]
[group by {col-name | expr | position}]
[having where_condition]
[order by {col_name | expr | position}]
[limit {[offest,] row_count | row_count offset offset}]이게 select를 통해 만들 수 있는 구문. 하위 인자들이 있다고 보면 편하겠다.
이 중에서 가장 많이 쓰이고 기본적인 게 .select from where인 것.
select from

use를 통해 사용할 데이터베이스를 특정한다. 안 한다면, select * from market_db.member를 쓰면 되기는 한다.

특정 열만 보고 싶다면? ,을 이용해서 쓴다. 순서는 내가 원하는대로! 여기에서 특정 열에 별칭을 붙여줄 수도 있다. 사용법은 간단하게 바로 뒤에 큰따옴표를 써서 나타낸다.

where
이제 where 절을 써보자. 특정 조건을 걸면 된다! 이때 등호는 하나만 넣는다는 것을 유의하자.

논리 연산자는 사용법이 똑같다.

근데 유용한 게 있다. 우리는 1부터 5의 범위를 나타낼 때 통상 두 개의 식을 세워야만 하는데, 여기에서는 between이란 것을 쓰면 된다! 범주형에 대해서는 in을 써서 범위를 나타낸다.
between으로 키의 범위를 잡고, 주소는 in으로 묶어서 and를 통해 교집합에 해당하는 행을 찾았다.
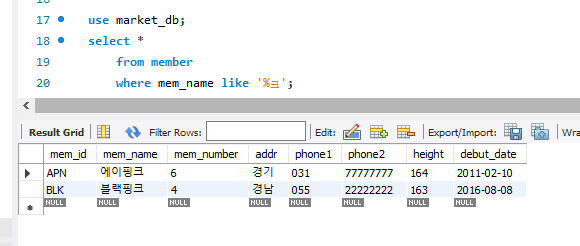
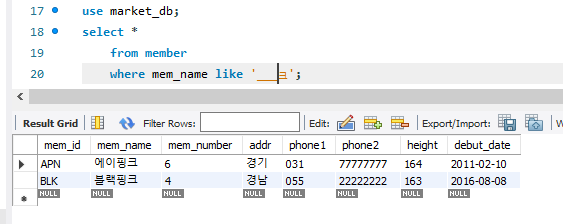
like를 통해 매칭되는 이름을 검색하는 방법도 있다. %는 얼마나 많은 글자가 올지 상관하지 않겠다는 뜻이다. _는 글자의 개수를 특정해준다. 후자의 그림은 언더바를 3개를 주어서 총 4글자면서 끝이 '크'인 그룹을 찾은 격이다.

서브 쿼리라고 부르는 것도 있다. 쿼리 속 쿼리, 잘 보면 안 속에 select문이 들어간 것을 확인할 수 있다. 내부 select문의 결과는 height 164이고, 이를 곧이곧대로 where문에 사용하여 나타내는 것이 가능하다!
- select
- from
- where
between, in - 서브 쿼리
3-2. 좀 더 깊게 알아보는 select 문
이번에는 위에서 본 더 심화된 구절들을 사용해보자.
order by
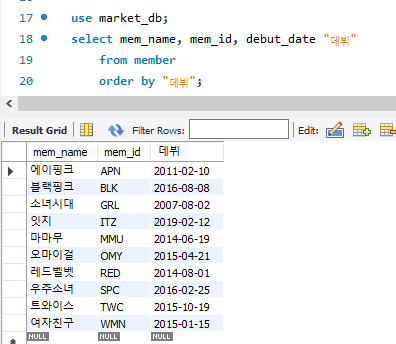
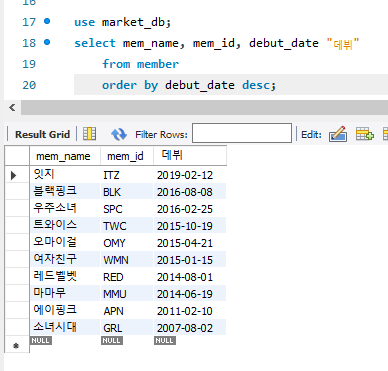
order by는 해당 열에 맞춰 정렬을 하는 기능이다. 나는 내 맘대로 별칭을 넣어서 해봤는데, 별칭을 사용할 경우 정렬이 되지 않는 것을 확인할 수 있었다. 기본적으로는 오름차순인 asc로 정렬이 되는데, 뒤에 desc를 넣어 내림차순으로 정렬하는 것도 가능하다.
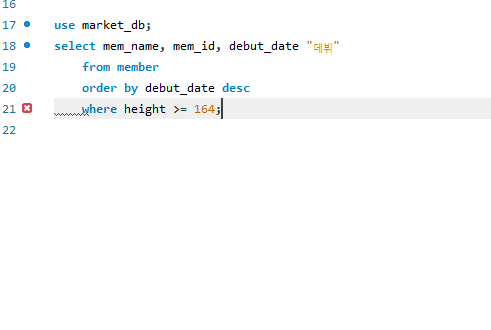
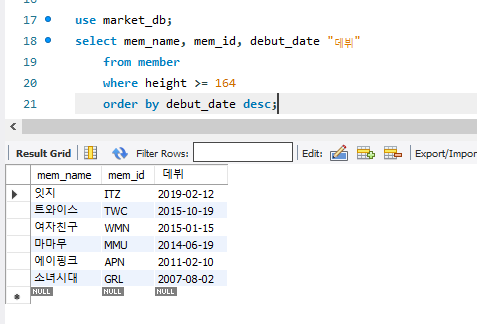
놀랍게도 where문과 함께 쓸 때는 where이 먼저 나오도록 해야 한다. 정렬하고 내가 원하는 놈 고르나, 원하는 놈 고르고 정렬하나 결국 결과는 같지 않나 싶은데, 그래도 효율적인 방향으로 코드가 작동되도록 제동이라고 걸어둔 것일까?
일단 아무튼 select의 절들은 되도록 순서를 지켜줘야한다고 한다.

order by에는 조건을 더 걸 수 있다. 단순하게 쉼표로 구분해서 넣어주면 된다.
limit
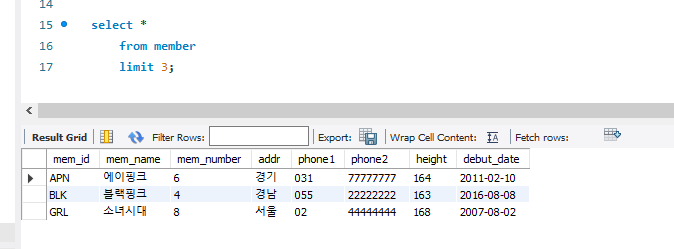
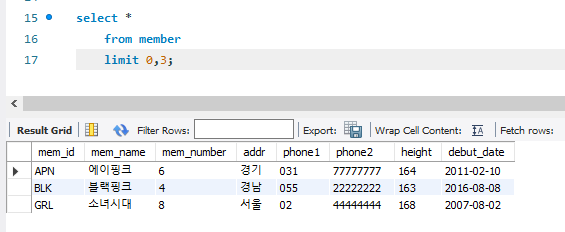
limit은 출력의 제한을 건다. limit은 두가지 인자를 쓴다. 시작하는 위치와 갯수!
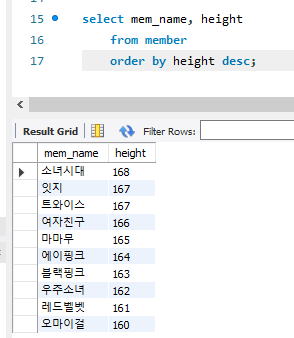
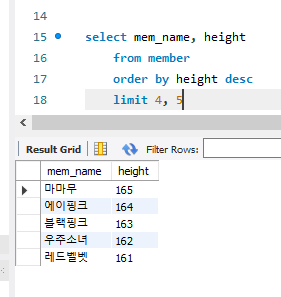
4를 썼으니 5번째의 마마무서부터 시작해서 5개의 행을 보여준 것!
distinct
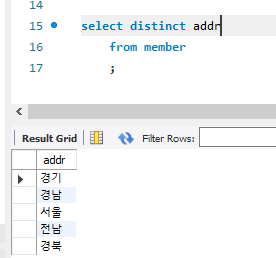
앞에 distinct를 붙이면 중복값을 제거하고 값을 볼 수 있다. 판다스의 unique를 쓰는 꼴이다.
group by
그룹바이는 묶어주는 역할을 한다. 판다스의 groupby가 데이터베이스에서 제공하는 기능을 따온 것으로 알고 있다.

가령 이러한 상황에서, APN의 합을 한번에 구하고 싶은 것이다. 이것을 손으로 일일히 구할 거면 굳이 mysql을 쓸 이유가 없다. 이때 groupby와 집계 함수를 쓰면된다!
sum(), avg(), min(), max(), count(), count(distinct)
대충 이런 집계 함수가 있다. 가장 마지막 것은 nunique를 세는 것이다.
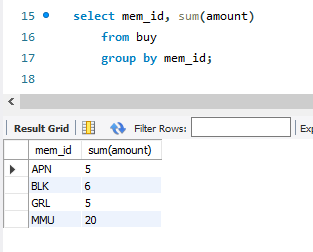
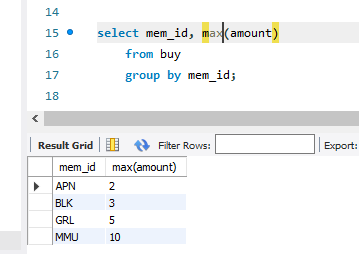
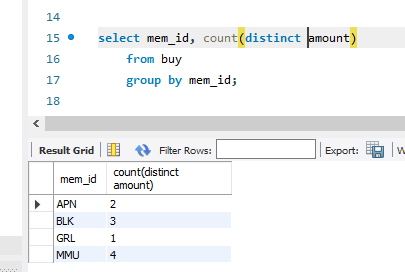
이런 식으로 활용하면 된다. 그룹바이를 쓴 다음, 집계함수가 꼭 있어야 명령이 작동한다.
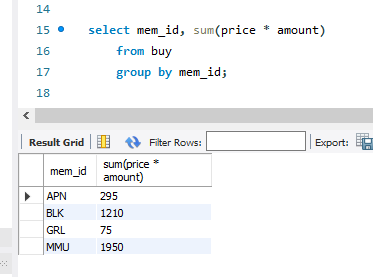
집계함수와 groupby 사용 방법. 집계 함수를 쓸 때 *를 쓰면 null도 같이 세게 된다. 어찌 보면 당연한 사항.
having
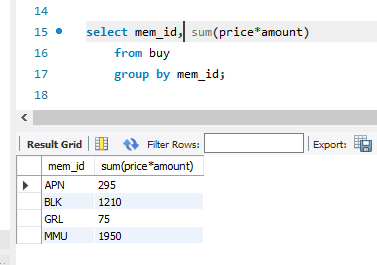
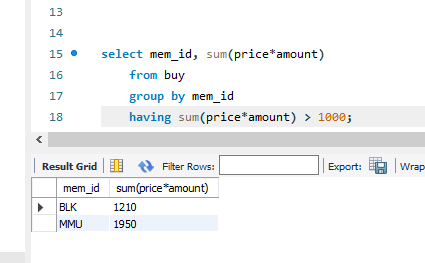
집계 함수에 대해서 조건을 걸고 싶을 때는 where을 사용하지 않고 having을 사용해야 한다. 그렇지 않으면 오류가 난다.

이게 나타내는 게 무엇인가? 한번 구매 횟수가 최대 4회를 넘긴 적이 있는 팀을 모아서 그 팀이 구매에 소모한 비용을 나타내는 것. 이런 해석을 해내는 데에 익숙해질 필요가 있다.
3-3. 데이터 변경을 위한 sql 문
테이블 한번 만들면 끝인가? 아니다 입력도 하고, 수정이나 삭제도 해야 한다.
insert
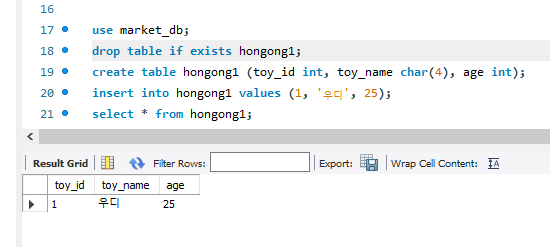
기존 예시에 내가 조금 추가한 것. 이 코드를 다시 실행하려니 이미 hongong1이 있다면서 안 되길래 처음에 있다면 삭제한다는 명령어도 넣었다.
'insert into 테이블 values 값' 방식으로 사용한다. 이때 값은 생략이 되어도 상관이 없다. 이때 순서는 지켜줘야만 한다고.

순서도 안 지키고 싶고, 결측값도 넣고 싶을 때의 방법. into 부분에 어떻게 넣을지를 명시해준다.
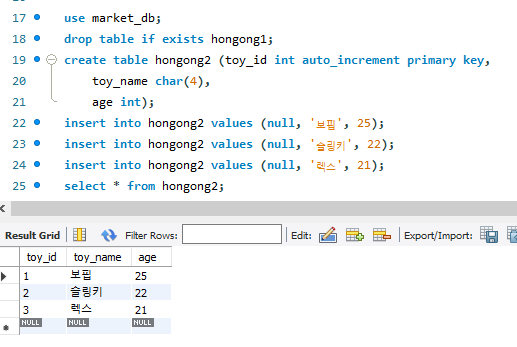
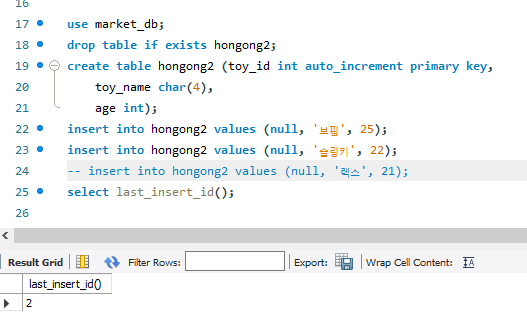
자동으로 1씩 올라가는 값을 넣고 싶다면 auto_increment. 꼭 해당 열을 기본 키로 지정해줘야만 사용이 가능하다.
오른쪽 사진은 last_insert_id()를 통해 마지막으로 들어간 숫자를 알 수 있다는 것을 나타내는 샷!
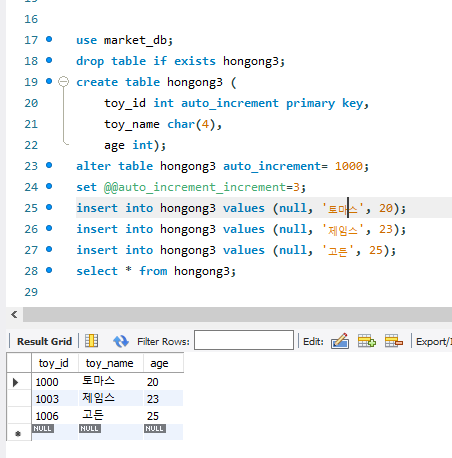
set을 통해 전역 변수를 관리할 수 있다. 대충 500여 가지가 넘는 전역 변수가 있으며 이들을 부를 때는 앞에 @@를 붙인다. 아무튼 alter를 사용하여 자동 상승 수 시작을 1000으로, 상승량을 3으로 올렸다. 결과적으로 toy_id는 1000에서 출발하여 3씩 오르고 있다.

참고로 이렇게 한 줄로도 나타낼 수 있다.
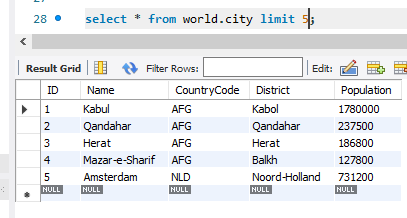
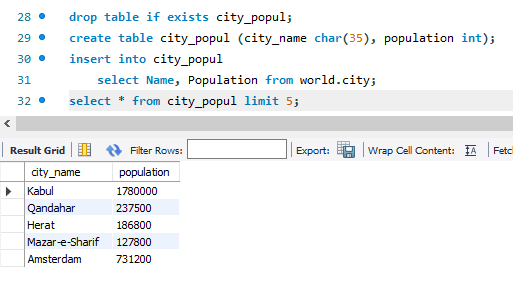
다른 데이터베이스에 있는 값을 그대로 넣어주는 것도 간단하다. 뭐 대단한 문법을 새로 보여주는 건 아니다. insert into는 뒤에 select를 통해 값을 베껴오는 것을 동작을 한다. 이때 넣을 테이블의 열과 들어가게 될 데이터의 열을 잘 맞춰주는 작업은 필수이니 주의하자.
update

업데이트는 추가하는 것이 아니라 있던 값을 수정하는 행위이다. 그런데 이것을 하려면 워크벤치에서는 위의 설정을 체크 해제하고 재시작을 해야한다고 한다.

보다시피 update할 테이블을 정하고, 무얼 바꿀 건지, 어떤 조건에 해당하는 녀석들을 바꿀 건지를 정한다. 만약 where 절이 없었더라면 테이블 내 모든 city_name이 서울로 바뀌어버렸을 것이다. 그런 식의 활용도 가능은 하다는 것.

한꺼번에 여러개의 설정도 바꿔줄 수 있다. 이젠 뉴욕은 유령도시가 되어버렸다.
delete

update와 비슷하게 사용하는 삭제 명령어. 조건을 걸어서 행들을 삭제해버린다. like하면 해당 문장에 맞는 것들을 골라준다. limit을 걸면 상위 5개만 삭제하는 것도 가능하다.
이것만 삭제 방법은 아니다. 삭제에는 delete, drop, truncate의 3가지 방법이 있다.

대용량 테이블의 삭제를 보면서 각 명령어를 비교하기 위해 세 테이블을 만드는 중. 갑자기 실행이 느리길래 렉걸린 줄 알았는데 확실히 대용량이라 create하는데 3초의 시간이 걸렸다.

각 명령어로 삭제하는 시간을 봤을 때, delete가 단연코 오래 걸린다. 다른 것들은 순삭. drop은 테이블 자체를 없애버리고, 나머지는 빈 테이블을 남긴다. 그럼 뭐하러 delete 쓰나? truncate는 where 같은 조건을 걸 수 없게 되어있다. 그러므로 정말 행 데이터를 전부 삭제하고 싶을 때만 truncate를 쓰는 것이다.