20221127일-라이트닝1~2, 밑러닝14~19, 리트코드
밑러닝-14. 같은 변수 반복 사용
저번 시간에는 자동미분이 되도록 구현하고, 더 다양한 연산을 할 수 있도록 가변 길이 인자를 받을 수 있도록 조치를 했다. 그러나 아직 완성은 되지 않았다. 왜냐하면 같은 변수가 들어갈 때 현재의 코드는 대입을 시키는 연산을 하기 때문에 값이 더해지지 않고 덮어씌워지기 때문이다.
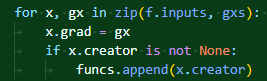
각 함수의 입력 변수에 대해 미분값을 넣을 때, 단순하게 대입을 하고 있는데, 이런 경우에 x+x 같은 연산에서 문제가 발생하게 된다. 실제 미분값은 2x이기에 2가 되어야 마땅한데, 해당 코드는 1이 나오도록 만들어져 있다.

해결 방법은 매우 간단하다. 그냥 더해주도록 만들어주면 된다!

참고로 이 두 연산은 작동이 조금 다르다. 후자는 덮어씌우는 연산으로 사용된 메모리 주소를 그대로 활용하는 반면 전자는 새롭게 메모리 주소를 할당한다. 분명 후자가 메모리적으로는 효율적이나, 후자의 코드를 짜는 경우 결과적으로는 모든 미분값이 같은 메모리를 참조하게 되는 불상사가 발생하게 된다.


전자와 후자의 명확한 비교. 후자는 그냥 말 그대로 전부 더하기만 했다. 이런 불상사를 막기 위해서 전자의 방식으로 코드를 짜야 한다!

마지막으로 변수 객체에 이러한 메소드를 추가해서 사용하자. 메모리 절약 등의 이슈로 같은 변수를 재사용해야하는 경우에 대해서 수동적으로 변수의 미분값을 초기화시킬 수 있게 해두는 것이다.
밑러닝-15. 복잡한 계산 그래프(이론 편)
여태까지는 단순한 모양의 함수 식만을 사용해왔지만, 장차 같은 변수를 반복 사용하거나 다양한 입력을 받는 식을 만들어나가는 게 우리의 목표이다.

draw.io를 통해서 쉽게 책에 있는 그림을 나타낼 수 있다! 아무튼 간단하게 이러한 함수가 있다고 쳐보자고. 동그라미는 변수, 네모는 함수! 정상적인 역전파라면 a변수에 미분값을 기록할 때 B,C에서의 미분값을 전부 가져와야만 한다. 함부로 X까지 바로 진행되어 미분값을 기록하는 일이 일어나면 안 된다는 것. 그러나 현재의 함수는 그러한 순서를 제대로 고려해줄 수 없도록 만들어져 있다.
현재의 역전파는 미분할 함수를 append와 pop만을 활용하기 때문. 마지막으로 들어간 녀석이 먼저 나와 미분이 진행된다. 요컨대 현재 미분 함수 순서가 D, C, A, B, A 순서가 되어버린다는 말이다. 우리가 원하는 순서는 D, C, B, A이다(C,B의 순서는 아무래도 좋다).
우리는 함수들의 미분 순서를 정확하게 정해주고 싶다. 우선순위가 있다 이 말이다! 이를 위한 방법으로 위상 정렬 알고리즘이란 것이 있다. 25. 위상 정렬(Topology Sort) 혹시나 검색해봤는데 내가 알고 있는 개념이 맞긴 하네. 진입 차수를 따져서 순서를 정해주면 된다. 그러나 사실 굳이 이럴 필요도 없다. 왜냐하면 우리는 순전파 과정을 한번 겪기 때문에 그 당시에 바로 순서를 정해주면 되기 때문이다.

아 이거 써보니까 더 쉽게 그림을 그릴 수 있는 방법이 있었네.. 암튼. 변수와 함수의 관계를 보자고. 저 네모를 기준으로 세대를 나눠주면 만사 ok라는 것. 세대 분기의 조건은 함수가 변수를 만드는 시점이다. 이것만 적절히 고려된다면 세대 순서대로 역전파를 진행하면서 우리가 원하는 결과를 얻을 수 있게 될 것이다.
밑러닝-16. 복잡한 계산 그래프(구현 편)

이제 저 아이디어를 코드로 구현해보자. 변수 객체에서 먼저 세대를 기록하는 변수를 만든다. 그리고 창조 함수를 저장하는 부분에서 자신을 창조한 함수보다 아래 세대가 되도록 코드를 짜준 모습.

함수 객체에서는 자신의 입력을 확인하고 그 중에서 가장 늦는 변수의 세대에 맞춰준다.
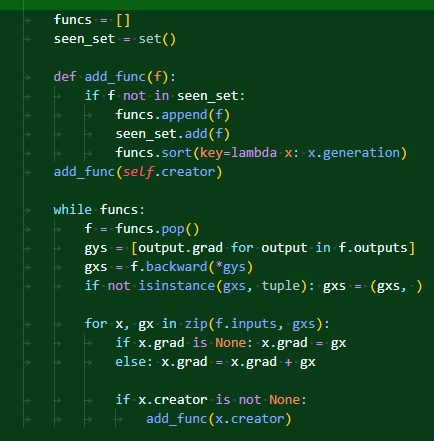
이제 세대를 기록할 수 있게 되었으니 세대에 맞춰 역전파를 진행하도록 만든다. 함수 속에 함수를 중첩 함수라고 부르는데, 함수 속의 변수들로 함수 속에서만 사용될 때 이런 모양을 만드는 것이 가능하다. 아무튼 seen_set이라 하여 혹여 이전에 한번이라도 들어왔던 함수가 아닌지도 체크를 하도록 만들어져 있다. 그리고 sort를 통해 세대 정렬을 매번 해주는 방식으로 작동을 하게 되는 것이다.

이제 위에서 원했던 방식으로 함수가 작동할 수 있게 되었다!


seen_set이 있고 없고의 차이를 보자. x.grad의 값도 분명 바뀌는데, 내부에서는 어떻게 작동하는가? 보다시피 seen_set이 없을 경우 마지막에 같은 함수 객체가 한번 더 리스트에 담기게 된다(메모리 주소를 잘 보면 정확한 비교가 가능하다)! 왜 그러한가?

이 부분에서 역전파가 일어날 때, a로 들어가는 함수가 두 개이기 때문에 A를 리스트에 넣으려는 add_func도 두 번 호출되게 된다. 그러나 우리는 이미 a에서 분기된 미분값을 다 계산하고 한번만 A로 넘어가면 되기에, A에 대해서 두 번이나 backward을 할 필요가 없는 것이다. 이를 방지하기 위한 수단으로 seen_set이 들어가있는 것이며, 결과적으로 후자는 미분을 불필요하게 한번 더 미분을 진행하게 되어 x에 틀린 미분값이 저장되게 된다.

정렬을 사용할 것이라면, 당연히 우선순위 큐를 활용하는 것이 바람직할 것이라 생각해서 진행해보려 했으나..

이런 문제가 발생했다. < 같은 연산자는 나는 쓰고 있지 않는데 나오는 이유는 아무래도 heapq의 내부 구조에서 나오는 것이 아닐까? 같은 세대의 함수들이 들어갈 때는 f.generation 뒤의 f에 대하여 비교를 하면서 큐에 담기게 될 것이다. 그러나 이때 f는 <__main__.Square object at 0x000001EA54016D90> 이런 식의 값이기 때문에 연산이 이뤄지지 않는 것이다. 그럼 어쩌냐? 음. 어쩌지? 어차피 같은 세대 내에서는 어떤 순서로 있어도 상관이 없지 않을까? 그렇다면 각 함수가 가지는 고유한 값, 즉 메모리 주소를 활용하여 추가적으로 순위를 정할 수 있게 고려해주면 좋을 것 같다.

클래스의 속성이나 메소드 중에 메모리 주소를 명시해주는 놈이 있지 않을까 하고 찾아봤는데, 그런 건 딱히 없는 듯. c언어였으면 & 이것만 넣어주면 쉽게 주소를 알 수 있는데.. 이런 점은 또 불편할 수도 있구나. 생각해보니 그냥 문자열로만 인식하게 해주면 된다.
근데 왜 미분이 제대로 진행되지 않는 것일까? 아래가 정상적인 미분인데 왜 미분값이 32밖에 나오지 않았을까?

정답은 꺼낼 때 순서가 잘못 돼서! 음수를 걸어주니까 값이 제대로 나온다. 우선순위 큐는 작은 값부터 뱉어주기 때문에 값이 높을수록 이후 세대를 뜻하는 우리의 변수에 대해서는 음수를 적용해야 원하는 순서대로 값이 작동하게 된다.
여태 배운 바로는 역시 우선순위큐를 사용하는 것이 바람직하지 않나 싶다. 끽해야 2logn이 nlogn보다는 낫잖냐?
스터디원들과 이야기해보고 이것을 어떻게 할지 정하면 좋을 것 같다.
밑러닝-17. 메모리 관리와 순환 참조
여태까지는 최대한 단순하게 구현을 하는 것을 기본으로 삼았지만, 프레임워크가 점차 커감에 따라 메모리 사용량이나 시간 복잡도도 차차 고려해야만 한다. 이번 단계에서는 메모리를 낭비하지 않는 방법을 알아본다.
참고로 파이썬은 프로그래밍 언어이지만, 파이썬을 실행하는 프로그램 자체도 파이썬이라 부른다(명령어 자체가 python). 그리고 흔히 이 파이썬 인터프리터는 c언어로 구현된 cpython을 사용한다. 이전에 영상으로 보기로 cpython은 아직 완전히 완성되지 않아서 더 개선의 여지가 있다고 들었는데, 이게 맞다면 장차 파이썬은 더 빨라질 여지가 있다.
파이썬은 쓰이지 않으면서 다시 참조할 수 없게 된 메모리를 삭제해준다. 이 덕분에 우리는 쉽게 OOM에 문제에 빠지지 않고 파이썬을 사용할 수 있는 것인데, 두 가지 방식으로 파이썬은 메모리를 관리한다. 참조 수를 세는 참조 카운트, 세대를 기준으로 쓰이지 않는 객체를 회수하는 세대 별 가비지 컬렉션(Generational Garbage Collection).
일단 참조 카운트 식의 메모리 관리가 무엇인지 보자. 방식은 간단하다. 참조가 되면 1을 증가시키고, 참조가 끊기면 1을 낮춘다. 그리고 해당 값이 0이 되는 순간 메모리를 회수한다. 참조 카운트는 대입이 이뤄질 때, 함수나 객체에 인자로 전달될 때 증가하고 반대로 함수나 객체를 나올 때나 참조가 끊길 때 줄어든다.
a = B
a = None대충 이런 코드가 있다고 하면 B라는 객체(파이썬의 모든 단위는 사실 객체이다)는 대입을 통해 참조 카운트가 1 증가했다가 다른 것이 새로 대입되는 바람에 대입이 끊겼다. 그래서 참조 카운트가 줄어들어 바로 메모리에서 공간을 뺏기게 되는 것이다.
그러나.. 이 방식에는 문제가 있으니 바로 순환 참조를 할 때 제대로 카운트를 줄이지 못한다는 것이다.


책에서 나온 예시. 중간 코드로 인해 각 객체는 참조 카운트가 1씩 늘어난 상태이기에, 단순하게 마지막 코드를 통해서 참조 카운트를 줄여도 옆 그림처럼 서로를 순환 참조하고 있는 케이스가 생긴다. 물론 저 관계를 다 일일히 끊어준다면 또 어느 정도는 해결되겠지만, 그래도 참 불필요한 과정을 거쳐야만 한다. 결국 사용되지도 않을 메모리가 계속 남게 된다는 것.

Garbage Collection in Python. Python의 메모리 관리 기법을 알아보자 이 링크에서 제시하는 순환 참조의 예시. 오호.. 이런 식으로도 코드를 짤 수 있다는 것에 새삼 놀랐다.
이것을 해결하는 것이 바로 세대별 가비지 컬렉션이다! 간단하게는 세대를 나누고, 세대별 임계값을 나눠서 2세대를 넘는 객체들을 삭제하는 방식이라는 것 같다. 그래서 순환 참조도 결국 잘 처리가 된다. 다만 메모리를 한계까지 끌어올려서 써야 할 수도 있는 딥러닝에서는 GC가 마냥 청소를 해줄 때까지 기다릴 수 없다. 그래서 순환 참조를 처음부터 만들지 않는 방향으로 코드를 짤 필요가 있는 것이다.

우리의 프레임워크는 여기에서 순환 참조 구조를 가지고 있다. 이를 해결하면서, 우리가 쓰고자 하는 방식대로 코드를 그대로 유지하려면 '약한 참조'를 해야만 한다. 참조는 하되, 참조 카운트를 증가시키지 않는 참조!

weakref라는 라이브러리를 활용한다. 보다시피 b를 함수처럼 활용하면 해당 값을 꺼낼 수 있다. 또한 b에 아직 참조가 되고 있음에도 a 대입을 끊자 dead가 뜨고 메모리가 회수된 것을 확인할 수 있다.


함수 객체에서 출력값을 저장할 때 약한 참조로 변경한다. 이후 output은 함수 방식으로 사용해야 값에 접근할 수 있으므로 오른쪽 스샷처럼 gys에서 output을 사용할 때 뒤에 괄호를 붙여주면 끝.
밑러닝-18. 메모리 절약 모드
이제 순환 참조는 막을 수 있게 됐고, 진짜로 메모리를 절약해보자.
사실 우리는 역전파를 진행하면 각 변수 객체의 미분값이 생기게 된다. 그런데 실제로 우리는 처음 넣은 값에 대한 미분값만 궁금하다.

retain_grad란 인자를 추가해서 중간 미분값을 남길지의 여부를 지정하게 한다. False일 경우, 반복문을 같이 돌면서 사용된 미분값을 바로 바로 삭제한다.

중간이라고 볼 수 있는 t, 그리고 y까지 성공적으로 미분값이 삭제됐다. 간단하게나마 순전파 자동미분보다 역전파가 좋은 이유가 밝혀지는 듯?
중간 미분값을 이렇게 없앨 수 있지만, 사실 더 필요없는 것도 있다. 미분은 학습할 때 이뤄지는 것이다. 그러나 예측을 진행할 때는? 미분을 위해 사용되는 값들이 하등 쓸모 없어진다. 역전파를 위해 함수 객체에 남겨두던 input값들 역시 싸그리 날아가도 된다. 이렇게 순전파만 하는 경우를 위해 역전파 여부를 껐다 켤 수 있게 만들자.

Config 클래스를 만들고 속성을 하나준다. 그것으로 조건을 걸어 역전파에 필요한 정보들을 담을지 말지 결정하는 것이다. 근데 그냥 변수 하나를 만들면 되는 것 아닐까? 왜 굳이 클래스로 만들어야만 하는 걸까?
일단 with를 통해 이를 더 간편화시켜줄 수도 있다. 예측에서만 역전파는 비활성화되기에, with를 써서 일시적으로 역전파를 안 하도록 만드는 방법이 유효하다.

책 내용을 얼추 보면서 빠르게 감이 오지 않아, 그냥 간단하게 구현할 방법은 없는 걸까 하고 시도해봤으나 실패한 코드. 아직 내가 with문을 완벽하게 알고 있지 않은 모양이다. with문을 통해 거치는 함수에 finally를 걸어 해당 함수가 닫히고 난 이후에 할 행동도 지정해줄 수 있는 모양.
yield는 보아하니 return과 비슷하게 동작하는 명령어라고 한다. 다만 값을 제너레이터라는 iter이면서 메모리에 당장 올라가있지 않은 형태의 객체를 반환하는데, 그냥 쓰면 아무래도 return과 같이 작동하는 모양.

아무튼 with 문으로 작동하기 위해서는 __enter__와 __exit__이라는 메소드가 있어야 하는 모양인데, 이를 위해 contextlib 모듈을 불러서 데코레이터로 사용하면 편하다.


yield가 무얼 하는 놈인가, 순서는 어떻게 되는가 더 자세히 알아보는 중. 일단 good의 위치가 바뀌는 게 잘 보인다. yield를 거치면서 with 식 자체는 끝나게 되고 그 이후 with에 걸린 코드가 실행되는 듯하다. finally가 항상 마지막에 온다.

yield가 없으면 작동하지 않는다. return하고 똑같나 했는데 그건 또 아닌 모양이다. Python Yield란?? What is the Yield?? :: 컴퓨터를 다루다 (tistory.com) yield는 잠시 함수를 정지시키는 역할도 한다. 아무래도 이 원리를 통해 값이 바뀌었다가 원상복구되는 동작을 구현하는 모양이다. 이때 이 함수에는 예외를 발생하는 경우가 있기도 한데, 이를 방지하기 위해 try구문을 써서 묶어준다고 한다.

요컨대 사실 그냥 이런 동작도 가능은 하다는 것. 요지는 yield를 하는 전에 전처리, 이후에 후처리 코드를 넣어주면 된다는 것이다.
와 이거 되게 어렵네..? 아직 팍 감은 오지 않는 것 같다.


다시 tmp로 만들려고 해봤으나, 원하는 대로 작동하지 않는다. 내 예상으로는 오류가 발생해야만 하는데 이 왜인지 너무 잘 작동한다.

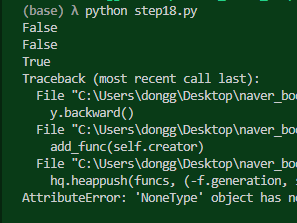
그러나 클래스를 활용하면 분명하게 에러가 발생한다. 일단 클래스를 사용해야 하는 이유는 이제야 알겠다. 왜 클래스만 잘 되는지에 대한 이유는 모르겠지만..
그래도 일단 당장 알아야 직성이 풀릴 것 같은 사항들은 대충 알아봤으니 넘어가도록 하자.

최종적으로 구현하게 되는 코드. getattr을 사용하여 클래스 속 속성에 접근하는 것 때문에라도 클래스로 묶는 것은 유용한 듯하다. 아무튼 미리 이전 값을 불러논 후에 잠시 false로 바꿨다가, 끝날 때 다시 이전 값으로 되돌리는 동작을 진행한다! 어차피 기본을 True로 설정할 것이라 사실 더 간단하게 코드를 바꿔도 상관은 없을 것이다. 해당 함수를 길게 쓰기 귀찮기에, no_grad라는 함수로 묶어주기만 한다.
내가 의도한 대로 no good까지 출력된 이후에 에러가 발생했다.
와 씨 개어렵네 ㅋ; 아무튼 이걸로 torch.no_grad() 구문이 무엇을 뜻하는지도 알게 된 셈이다. 레벨 1 때 한번 질문거리로 나왔던 내용인데, 내가 이 책을 일찍이 읽었다면 그 시절의 대화는 더 진전될 수 있었으리라.
더 제대로 알면 좋을 것 같은 내용은 contextlib, yield, class로 묶는 것. 당장 여기에서 어떻게 쓰이는지는 확인을 했지만, 더 정확하게 알고 있는 것 같지는 않아 스터디에서 이야기가 나오면 좋을 듯 싶다.
밑러닝-19. 변수 사용성 개선
이제는 조금 쉽게 쓸 수 있게 만들어보자!

변수에 이름 정해주기. 이름을 붙이면 추후 시각화를 할 때 도움이 된다고 한다.

다음, 넘파이에서 ndarray에 대해 정보를 얻을 때 쓰는 각종 메소드들을 활용해보고 싶다면 이렇게 추가해주면 된다. 위에 데코레이터를 씌워줬는데, 이는 메소드처럼 괄호를 붙여야만 쓰지 않고, 단순하게 속성을 부를 때처럼 호출할 수 있도록 해준다.
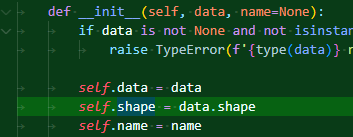
당연히 그냥 이렇게 일찌감치 속성으로 만들어서 하는 것도 가능은 하다. 굳이 위처럼 하는 이유가 있는 걸까? 얼핏 기억하기로는 보안성? 클래스의 값들을 클래스 외부에서 함부로 고칠 수 없도록 하기 위한 장치라는 것 정도로 기억이 나는 것 같기도 하다.
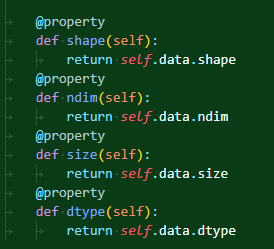
아무튼 같은 방식으로 다른 것들도 몇 개 추가해준다. 필요한 것이 있다면 알아서 추가하라고 하네.


len과 repr를 통해 진짜 넘파이에서의 일반 변수처럼 만들어버렸다! 우리야 결국 print 찍힐 때 나오는 모습으로 결국 변수를 확인하는데 이렇게 되면 진짜 변수 객체로 둘러쌓이지 않은 것처럼 활용할 수 있을 것이다.


내가 알기로 str관련 매직 메소드도 있다는 것으로 알고 있어서 시도를 해봤다. 근데 내가 의도하지 않는 결과가 나와 조금 놀랐다. 아무래도 str 매직 메소드는 str으로 self를 묶기만 하면 발동되는 모양이다. 덕에 self.data이든, 무엇이든 묶기만 하면 __str__로 넘어가는 듯.. 왜인지 중간에 혹시나 해서 걸어둔 중간 print문은 작동하지도 않는데 왜 그런지는 잘 모르겠다.
라이트닝-Level 1: Train a model

들어가기에 앞서 라이트닝의 장점. 구조가 간단해진 코드를 통해 유연하게 모델 적용이 가능하다. 여타 테스팅을 진행해준다는 듯. 무엇보다 내가 보기에 좋아보이는 것은, 알아서 cpu, gpu 처리를 해준다는 것. 로컬마다 환경이 다를텐데 이를 알아서 간편화시켜주는 것은 퍽 편리해보인다. 또한 중간중간 cpu와 gpu를 넘나드는 연산이 필요한 것도 요컨대 라이트닝이 다 알아서 처리해준다는 뜻인가? 그렇다면 충분히 메리트 있어 보이긴 한다.

라이트닝은 코드만 경량화 시켜주면서도 효율성은 유지하는 모양이다. 이게 벤치마킹한 결과라는데, 흠. 근데 모델의 작동속도를 측정한 거라면 x값이 작아야 더 좋은 거 아니냐.. 크게 차이 안 나는 것을 장점이라고 이야기하고 있는 것일까?

간단하게 콘다로 라이트닝을 설치하는 방법. 나는 라이트닝으로 gcn 모델을 적용해보는 연습을 하는 것을 목표로 잡아보면 좋을 것 같다.

그러기 전에 튜토리얼을 제대로 밟아봐야겠지. 그냥 튜토리얼에 나온 내용을 그대로 쳐봤다. 일단 파이토치로 만든 모델들이 필요하다. 인자를 저장하고, forward 동작만 기본적으로 지정해주면 준비는 끝.

이후에 이 모델을 묶는 라이트닝모듈을 만든다. 모델으 인자로 넣고, training_step과정을 넣어준다. 단순하게 들어가야하는 x,y를 받고 그것을 모델을 돌린 후 손실만 구해서 반환. 아무래도 오토인코더라 라벨 값이 x로 쓰이는 듯.
아무래도 이름은 저렇게 고정을 시키고 사용을 해야 정상작동할 것 같다.
그리고 최적화를 해주는 메소드까지 지정해주면 끝!

최종은 더 간단하다. 데이터셋을 불러오고, 데이터로더에 넣어서 iter로 만들어준다. 그리고 최종 모델을 라이트닝모듈로 만들어진 녀석을 선언하고, trainer라는 또 인스턴스를 받아서 모델과 데이터를 넣고 fit.

해서 나온 화면이다. 이름은 라이트닝모듈에서 지정한 이름으로 되고, 타입은 해당 모델 클래스 이름으로 잡히는 듯하다. 이후에 인자 갯수는 알아서 계산해주는 듯.
중간 warning 내용은? 병목 현상이 일어날 수 있기에 num_workers를 늘려보라는 듯. DataLoader num_workers에 대한 고찰 (tistory.com) 이전에 강의로 배운 적도 있기는 하지만 이 글이 또 정리가 잘 돼있는 듯하다. gpu에 일을 시킬 때 cpu에서 몇 개까지 gpu에 일을 시키는 일꾼을 둘 것인가?에 관한 인자이다. 새삼 궁금해지는 것이 그럼 이 일꾼의 단위는 무엇일까?

프로세스 단위는 아닌 건가? 아니면 코어? 스레드? 라기에는 이런 것을 컴퓨터가 보통 그런 단위로 작업을 하지는 않지 않냐.. 가령 내 cpu는 6코어 12스레드인데 num_workers를 6까지만 줄 수 있다? 흠. 진짜 그런가? 다시 보니까 정말 그게 맞는 것 같기도 하다. 원격 서버로 돌리고 있는데, 한번 8개를 넣고 돌려보는 것도 괜찮을 듯.
에폭은 얼마나 돌아가는 것일까? 아무래도 디폴트 값이 따로 존재하는 모양이다.

미쳐버리겠네 ㅋㅋ 사실 라이트닝을 밑러닝보다 먼저 공부 시작했는데, 이게 너무 오래 걸린다 싶어서 돌리는 동안 밑러닝 공부를 하기 시작했다. 근데 밑러닝 공부가 끝났는데도 아직도 에폭을 돌고 있다. 음. 이건 좀 아닌 것 같다.

관두는 김에 한번 num_workers를 아예 8로 주고 한 모습. 근데 정작 v_num은 1이 찍히고 있는데, 이거 뭐 어쩌라는 거지..?

대신 다른 워닝이 새로 튀어나왔다. 음. 이거 내가 냅뒀으면.. 1000에폭을 돌았을 것이라는 뜻으로 받아들이면 되는 거냐..
혹시나 하는 마음에 조금 더 돌리면서 듀얼 모니터 설치 끝나고 그냥 포기했다. 될대로 되라지 뭐..

조금 정신이 없었는데, 일단 max_epochs을 설정해보라 했으니 한번 해보자고. 한번만 해서 된다면 실습으로는 괜찮은 정도라고 생각한다.

아, 드디어 멈추네. 하이고 장하다!
라이트닝-Level 2: Add a validation and test set
위의 과정에서는 검증셋을 나누지 않았는데, 이러면 112% 정도의 확률로 오버피팅이 발생할 수밖에 없다. 괜히 검증셋을 두는 게 아니지.

테스트셋을 예측하는 과정. 기존과 달라지는 것은 손실을 리턴하지 않고, 손실을 기록한다는 것. 아무래도 상위 모듈에서 로그가 정의되어 있는 듯하다. 단순하게 눌러서 확인할 수는 없지만, 로그 디렉이 생기기도 했다.
검증 과정 역시 똑같고 이름만 다르게 되어 있다.

검증 셋을 따로 데이터로더로 두고, fit에서 검증셋으로서 넣어준다.

그나저나 뭐가 계속 새로운 게 뜬다. 워닝이라면서, 거의 뭐 이것도 튜토리얼 정도로 주는 거 아니냐..? gpu를 쓰고 있지 않으니 이렇게 해서 쓰라는 건데, 그럼 진작 알려주지 그랬냐.
오버피팅을 막기 위해서는 적절한 타이밍에 끊는 것도 중요하다. 얼리스타핑도 있고, 최고 기록을 낸 에폭의 모델을 저장하는 방법도 있다. 얼리스타핑과 체크포인트.

이런 종류의 체크포인트들이 있다는 듯하다.

기본적으로는 이렇게 트레이너를 만들 때 저장할 위치를 설정한다. 기본적으로는 마지막 에폭을 저장한다고 한다.
이렇게 하파를 저장한다고 불러두면 알아서 저장이 되는 모양.

여기에서는 어떻게 그러한 값들에 접근할 수 있는지에 대한 방법도 나와있다.

이렇게 하라는 것으로 이해했는데, 제대로 작동하지 않는다. 추후에 다시 보는 게 좋을 것 같다.
모델을 저장하는 방법은 이 정도면 됐다. 그렇다면 어떻게 얼리스타핑을 할 수 있을까?
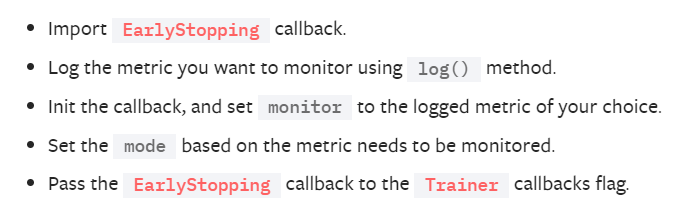
방법이 잘 나와있다.

간단하게 EarlyStopping을 임포트한 이후에 모니터할 값을 지정한다. 더 상세한 지정도 가능한 모양이다.

earlystopping에 줄 수 있는 추가적인 인자들.

아예 내가 얼리스타핑을 따로 커스터마이징해서 사용하는 것도 가능하다.
참고로 얼리스타핑은 기본적으로 모든 검증 에폭에 대해 적용된다. 그러나 이 주기를 변경할 수도 있고, 언제부터 얼리스타핑을 적용할지도 정해줄 수 있다.
지난 스터디 요약 정리
7. 역전파 자동화
변수 객체에 backward 메소드 추가, 이를 통해 함수 객체의 역전파가 재귀적으로 동작하도록 만들기.
Define-by-Run: 연결 구조를 정의해둔 채, 식을 실행하는 시점에 연산이 이뤄지도록 하는 방식.
변수와 함수의 관계: 변수에게 함수란? 자신의 창조자. 함수에게 변수란? 자신의 입출력.
8. 재귀에서 반복문으로
재귀보다 메모리 효율적인 반복문으로 역전파 자동화가 이뤄지도록 수정.
꼬리 재귀: 재귀 호출이 끝날 시 결과를 바로 반환하도록 하는 재귀문 방식.

후자의 방식을 통해 중간 재귀 함수들은 순수하게 계산이 완료된 결과만 전달하며, 꼬리 재귀 문을 인식하는 언어는 해당 재귀를 반복문의 형태로 변경하여 계산한다. 결과적으로 재귀의 형태를 취해 모양은 간단하게 하면서 반복문의 메모리 사용방식을 따를 수 있게 된다.
9. 함수를 더 편리하게
함수 객체를 사용할 때 함수처럼 사용이 가능하도록 수정.
자동 미분 진행 시 최종 값에 해당하는 y의 미분값 dy/dy, 1을 직접 대입하지 않아도 되도록 수정.
사용할 자료형을 ndarray로만 이뤄지도록 고정.
10. 테스트

unittest: 파이썬 내장 라이브러리로 python -m unittest 파일이름.py로 실행 가능하도록 만들어짐.
discover를 통해 디렉 단위의 테스트 진행도 가능.
11. 가변 길이 인수(순전파 편)
add와 같이 분기가 일어나는 연산이 가능하도록 수정. 함수의 입력값과 출력값이 리스트로 들어오고 나갈 수 있도록 만들기.
12. 가변 길이 인수(개선 편)
11에서 수동적으로 변수들을 리스트에 묶이게 설정해야 한다는 점을 개선.

*를 인자 앞에 붙여 입력값을 위치 가변 인자로 받아 클래스 내에서 알아서 리스트로 받도록 수정.
추출력값 역시 값이 하나가 반환될 때 알아서 튜플로 묶도록 수정.
13. 가변 길이 인수(역전파 편)
분기가 발생하는 하위 함수 객체에서 역전파 정의하기.
이에 맞춰 변수 객체에서 backward 진행 시 분기가 일어나도 전부 역전파가 진행되도록 수정.
스터디 정리
14. 같은 변수 반복 사용
같은 변수를 넣을 때 미분값이 덮어 씌워지는 것을 해결.
인플레이스 연산을 통해 새로 메모리를 할당하지 않고, 기존 메모리에 덮어씌우면 문제가 발생하기에 새롭게 메모리를 할당하는 방식으로 해야 함.
코드 이슈: 깃에 있는 기존 코드가 진도에 맞춰 업데이트 되지 않아 문제 발생.
clear_grad는 이후에 28단계에서 나올 수 있기에 나중에 다시 보는 것으로. zero_grad와도 연관될 수 있음.
15. 복잡한 계산 그래프(이론 편)
현재 역전파는 단순히 append와 pop을 활용하기에 순서가 제대로 반영되지 않음. 스택 형으로 역전파가 이뤄지기에 분기가 합쳐지고 나아가야하는 부분이 제대로 동작하지 않음.
역전파 시에는 위상(그래프의 연결된 형태) 차이를 고려해서 역전파를 할 필요가 있다.
residual connection, resnet에서 이뤄지는 연산의 경우 역전파의 순서가 제대로 고려될 필요가 있음. 그러나 책의 예시나 mlp구조같은 것은 사실 문제가 발생하지 않을수도 있음. 만약 행렬 연산으로 치환할 수 있는 연산이라면 하나의 변수가 들어간다고 치고, 분기가 발생하지 않는다고 간주하고 계산 하는 것 가능.
역전파가 두번 흘러들어가는 것은 무엇이 문제인가? 책에서의 예시에서는 이 부분도 문제가 되지 않을 수도 있음. 그러나 두번 연산이 이뤄지지 않고 한번에 역전파되는 것이 연산을 줄일 수 있어 좋을 것으로 생각됨.
여튼 역전파는 세대를 구분하여 역전파의 순서를 정해주는 것으로 해결이 가능.
16. 복잡한 계산 그래프(구현 편)
세대를 나타내는 변수 만들기. 함수와 변수 객체 모두 세대를 가짐.
역전파 시에 중첩 함수를 사용. 감싸는 메소드 안에서만, 그리고 그 안에서 정의된 변수만을 사용할 때 사용할 수 있음.
기존 역전파는 따지자면 dfs의 방식으로 이뤄지는데, 이를 위상 정렬된 dfs 방식으로 바꿔주는 작업을 하는 것이라 볼 수 있음. dfs를 하되 세대를 고려하면서 나아가는 방식.
우선순위 큐를 통해서도 구현 가능.
17. 메모리 관리와 순환 참조
파이썬은 불필요한 메모리 알아서 삭제. 그러나 원활한 메모리 사용을 위해 직접 코드를 수정할 필요 있음.
기본적으로 파이썬은 참조 카운트 방식이며 이는 순환참조 방식에서 문제 발생. 이것은 세대별 가비지 컬렉션에서 해결해줌.
weakref로 약한 참조를 걸어 간단하게 해결.
18. 메모리 절약 모드
메모리 사용 개선을 위한 두가지 방법.
retain_grad 인자를 만들어서 중간 미분값이 필요 없을 시 x값에 대한 미분값 제외 싹 다 삭제.
역전파를 하지 않는 모드를 개발. config라는 클래스 만듬.
with 문을 통해 모드 전환을 하며 이를 위해 데코레이터로 contextlib을 사용.
try/finally 구문이 없어도 사용은 가능. yield는 래핑을 하는 것과 비슷하게 동작하여 with 이후 구문이 돌아가도록 함.
클래스로 config를 만드는 이유. 스크립트 단위로 관리를 할 수 있게 하기 위함.
파이썬 파일 단위로 관리할 때 변수로 쓰는 것은 불가능.
토치에서 예측을 진행할 때 mode.eval()와 with torch.no_grad()를 사용. 이때 mode.eval()의 동작은 예측 시에 드롭아웃 같은 것이 일어나지 않게 막아주기에 필수이나, torch.no_grad()는 단순히 역전파에 필요한 메모리를 쓰지 않기 위함이기에 필수적이지는 않음.
19. 변수 사용성 개선
편의성 개선. 변수 이름을 정해주기. ndarray의 인스턴스 변수 지정.
왜 property 데코레이터를 사용하는가? 디자인 패턴과도 연관되는 것으로 클래스의 private 속성을 지켜주기 위함.
__repr__내에서 print문이 작동하지 않음. 자체적으로 막혀있는 것으로 보임.
라이트닝
mnist셋을 활용해 예제
num_workers를 많이 걸면 데이터가 적을 때 문제가 발생할 수 있음.
간단하게 mlp 모델을 만들어서 적용. 라이트닝이 있을 때와 없을 때의 각각의 코드 비교.
라이트닝은 라이트닝 모듈을 overriding하여 새로 클래스를 만든다.
sklearn을 쓰지 않고, Accuracy를 torchmetric에서 불러올 수 있음. 모양이 더 깔끔함!
training_step 메소드로 학습 진행여기에는 optimizer가 없음.
fit만 하면 알아서 model.train()을 진행. for문도 알아서 돌아줌!
on_train_epoch_end, on_train_batch_end, on_predict_epoch_end 등의 메소드도 존재. 이를 통해 더 다양한 조작이 가능함.
로그라는메소드가 따로 존재하며 dict 타입으로 로그를 저장하는 것도 가능함.
configure_optimizer 메소드 존재. 반환은 단순하게 optimizer. 이 역시 dict 타입으로 돌려줄 수 있으며, 이때는 이름을 정확하게 표기해야 함.
훈련 스텝, 검증 스텝, 예측 스텝이 따로 있음. 예측 스텝에서는 알아서 mode.eval과 no_grad를 알아서 해줌!
on_predict_epoch_end에서는 result 인자를 받아 끝나면 예측값 저장하도록 할 수 있음.
trainer를 만들어 에폭과 얼리스타핑, clipgrad를 지정할 수 있음. callback을 통해 다 커스터마이징 가능함.
v_num은 로그를 남길 때 기록되는 버전을 뜻함.
default_root_dir은 체크포인트가 저장되는 위치.
얼리스타핑. monitor인자로 어떤 값을 기준으로 할 것인지 지정할 수 있고, 이 역시 callback을 통해 세세한 조정 가능.
yaml을 써서 config 변수, 정보들을 관리하게 할 수 있음. NLP 레벨 1 게시판 참고!
omegaconf 임포트하여, yaml 파일을 파이썬에 적용할 수 있도록 함. hydra를 임포트에서 쓰는 것도 가능한 모양.
얼리스타핑. 파이토치로도 구현 가능하나, 파이토치는 베스트 모델을 알아서 구하면서 작동.
라이트닝은 조금 더 수정할 수 있게 돼있음.
얼리스타핑의 조건을 거는 세세한 조정은 라이트닝, 파이토치 둘다 overriding을 통해 구현함.
overriding. 상속을 받아서 부모에 정의된 함수를 덮어씌워 재정의하는 행위. 커스터마이징을 위해 사용됨.
callback. 학습 끝나고 끝날 때마다 보는. 다른 코드의 인수로서 실행가능하게 만들어둔 함수나 동작을 칭하는 용어.

Leetcode Weekly Contest

양수로 이뤄진 num 배열을 받고, 값이 다른 3 원소의 인덱스의 갯수를 출력한다. 이때 인덱스가 오름차순인 상태만 인정한다.
from itertools import combinations as cb
class Solution:
def unequalTriplets(self, nums: List[int]) -> int:
lst = [*cb(nums, 3)]
ans = 0
for a,b,c in lst:
if a != b and a != c and b != c:
ans += 1
return ans생각만 조금 바꾸면 쉽게 풀 수 있는 문제. 첫 문제라 easy한 편이다.


예시를 봐야 조금 이해가 되는 것 같다.
class Solution:
def closestNodes(self, root: Optional[TreeNode], queries: List[int]) -> List[List[int]]:
lst = []
tree = []
tree.append(root)
while tree:
tmp = tree.pop()
lst.append(tmp.val)
if tmp.left:
tree.append(tmp.left)
if tmp.right:
tree.append(tmp.right)
lst.sort()
ans = []
for i in queries:
tmp = []
start = 0
end = len(lst)-1
while start <= end:
mid = (start + end) // 2
if i > lst[mid]:
start = mid + 1
elif i < lst[mid]:
end = mid - 1
else: break
if lst[mid] == i:
tmp = [i, i]
else:
if mid == 0 and lst[mid] > i:
tmp.append(-1)
else: tmp.append(lst[mid - 1] if lst[mid] > i else lst[mid])
if mid == len(lst) - 1 and lst[mid] < i:
tmp.append(-1)
else: tmp.append(lst[mid+1] if lst[mid] < i else lst[mid])
ans.append(tmp)
return ans꽤나 어려웠던 문제. 처음에 $10^5$의 제한이 걸려있길래 순간적으로 수가 엄청 크다고 지레짐작했는데, 곰곰히 생각히보니까 10의 5승이면 끽해봐야 100000이잖냐. 그래서 처음 생각대로 트리에 들어있는 모든 값을 일단 lst에 넣고 정렬해서 이분탐색을 진행했다.
매번 이분탐색은 mid값이 무엇인지 헷갈리고는 하는데, 일단 직관적으로 코드를 짜고 테케를 돌려보면서 틀린 거에 따라 코드를 고쳤다.
덕에 항상 이분탐색은 정확하게 어떻게 동작하냐고 세세하게 말하기가 힘든데, 사용할 줄은 아는 이상한 상태다.

각 노드에서 중앙 0 노드로 오는데 드는 최소한의 비용을 구하는 문제. 문제에서는 차를 타고 오는 것으로 이야기한다. 이 차의 최대 탑승 인원 수 역시 입력으로 주어지며, 각 노드에서 차를 최대한 합승해 타면서 드는 비용을 계산하면 된다.
(1) [C++, Java, Python3] Simple DFS O(n) - LeetCode Discuss 직접 풀지는 못하고, 이 코드 참고하면 좋을 듯. 생각보다 굉장히 단순하게 구현을 할 수 있게 돼있다.
회고 및 다짐
누나가 긴 모니터를 장만하면서 내다버린 서브 모니터를 내가 줍줍하게 됐다. 와, 근데 이거 색감은 좋은데 눈이 되게 청색광이 많다고 해야 하나 눈이 금방 피로해질 느낌이다. 화면 크기도 내가 가진 것과 달라서(내것 기존이 27에 이번 것이 24이 것이다 아마), 마우스를 옮길 때마다 위치 파악도 제대로 안 된다. 커브드가 아니라 그런지 화면의 가장자리가 어둡게 느껴진다. 무엇보다 체감이 되는 것은 60프레임 제한.. 마우스 움직일 때마다 마우스가 순간이동하는 게 눈에 다 보이는데 이거 적응하는데 시간이 좀 걸릴 것 같다.
그래도 매번 화면에 다양한 것을 띄워둘 수 없어서 불편했던 점이 해결된다는 것이 이 모든 단점을 상쇄할 듯 싶다. 매번 기록을 위해 티스토리 창을 항상 옆에다 띄워두는 게 공간을 차지해서 불편했는데 이게 해결된다는 게 정말 크다.