20221031월-8th of Pstage
먼데이 챌린지
프로젝트에 손을 대야 한다는 마음에 계속 조바심이 들어 문제를 풀다가 그냥 도중에 끝을 냈다. 문제의 질에 대해서 이전에도 의심을 한 적이 있던 터라 크게 아쉽지는 않았다. 그래도 시간 여유가 될 때 한번 다시 빡세게 푸는 시간을 가져도 좋을 듯.
import sys
input = sys.stdin.readline
from collections import deque
n, m = map(int, input().split())
inlst = [[*map(int, input().split())] for _ in range(n)]
ans = 0
dx=[1,-1,0,0]
dy=[0,0,1,-1]
def check(x, y, m):
visited = [[0] * n for _ in range(n)]
count = 0
que = deque()
que.append((x,y,count))
while que:
x, y, c = que.popleft()
visited[x][y] = 1
if c == m: return False
for i in range(4):
nx,ny = x+dx[i], y+dy[i]
if -1<nx<n and -1<ny<n:
if inlst[nx][ny] == 2:
return True
else:
if visited[nx][ny]: continue
que.append((nx,ny,c+1))
for i in range(n):
for j in range(n):
if inlst[i][j] == 1:
if check(i,j,m): ans += 1
print(ans)첫번째 문제만 풀었다. 이번 문제들은 설명이 이상하게 돼있는 것도 없고 괜찮은 문제들인 것 같은데, 내 실력이 모자라 포기하는 것 같아 아쉽기도 하다.
import sys
input = sys.stdin.readline
from collections import deque
n = int(input())
dp = deque()
dp.append(0)
dp.append(0)
dp.append(1)
for i in range(3, n+1):
dp.append((2 * ( i - 1)+1) * dp[-1] + dp[-2])
dp.popleft()
print(dp[-1] % 100000007)이건 저번주 마지막 문제. dp로 풀어야겠다고 생각만 들었지만 끝내 점화식을 찾지 못해 포기했었는데, 해설을 읽어보니 확실히 어려워서 내가 못 찾을만 했다 싶었다. 원래 점화식 세우는 것은 천재들의 영역이라고..! 이것도 나중에 시간 되면 다시 파보는 게 좋을 문제.
데일리 스크럼
어제 이후의 진전이 있는지. 나는 어제 글에 적혀있으니 굳이 적지 않겠다. 현욱님의 정보. FM 계통의 가장 최신 버전 FMFM! 작년에 나온 녀석으로서 FM 계열에서는 가장 좋아보인다. 그래서 이 놈을 활용해보는 게 좋을 것 같다. 희원님도 이쪽을 파는 중.
범주를 묶는 방법. 나는 수작업으로 할 생각을 하고 있었는데, 복기 님 제시로 클러스터링을 하는 알고리즘을 쓰는 것도 방법이 있다는 것을 들었다. 그래서 그것을 간략하게만 알아보고, 적용할 수 있을 시 한번 해보고, 안 되면 그냥 내 손으로 하는 쪽으로 가야겠다.
범주 처리1
클러스터링 기법을 통해 범주를 처리할 수는 없을까? K-means 클러스터링을 찾아본 바, 무작위 중심값을 정하고 그것과의 거리를 계산하면서 군집을 만드는 알고리즘이었다. 그런데 이것은 범주형 데이터에 대해 적용할 수 있는 것인가? fiction과 animal의 거리를 어떻게 측정하는가?

범주는 여기에서 명목형에 속하는 데이터로 보인다. 클러스터링 분석 - (1) 범주형 변수 (tistory.com)
클러스터링 분석 - (1) 범주형 변수
클러스터링(군집) 분석을 하면서 고민했던 부분들을 조금씩 정리해 보려고 합니다. 분석 기법에 대한 이야기보다는 실무에서 클러스터링 분석을 진행하면서 고려할 부분이나 미리 염두에 두면
hweejin.tistory.com

해당 링크에서 나오는 내용으로, 범주형 데이터를 클러스터링하기 위해서는 결국 원핫인코딩이 필요하다. 라벨 인코딩은 순서형 데이터로 받아들여질 여지가 있어 불가능하다. 결국에는 사람 머리로 분류하는 일이 동반되는 게 좋다는 것이 이 글의 핵심인 것 같다.

상관 계수니, 유사도니 잘 모르겠어서 무턱대고 다른 사람의 코드를 그대로 따라쳐봤더니 나오는 꼴. corr()는 범주형 데이터가 조금도 고려되지 않는 것으로 보인다.
K-modes라 하여 범주를 어느 정도 묶어주는 알고리즘도 있는 것으로 보인다. 최빈값을 활용하는 식으로, K-means의 변형.

대충 이런 식으로 사용하는 것 같다. 근데 어떤 머시기 유사도를 측정하고 한다는데, 그게 정확하게 어떤 식으로 사용되는 것인지 아직 이해가 부족하다. 일단 사용해보고 그 성능을 확인한 뒤에 괜찮다 싶으면 더 파보자.

다른 것들은 모르겠지만, 일단 15번째 클러스터를 보면 fiction에 대해서는 확실하게 인지를 하고 묶어낸 듯한 모습이 확인된다.

거의 모든 것들을 잘 묶어낸 듯하다. 그러나 다른 것들에 대해서는 그렇게 잘 군집화를 성공한 것 같지 않다. 애매한 결과다. 생각해보면 데이터가 지나치게 불균형을 이루고 있어서 결국 사소한 영역은 인간이 손봐줘야 하는 것은 아닐까?

어차피 fiction이 가장 많으니 fiction따로 다른 것 따로 구분하는 것을 잘하는지 체크하고자 군집 수를 2로 설정했다. 일단 확실하게 fiction은 잘 잡아내는 모습이다. 그러나 그 속에 다른 것들을 너무나도 많이 포함한다.
그렇다면 내가 수작업을 조금 하고, 그 이후에 이런 군집화를 다시 시도해보는 것은 어떨까? 그것도 유효한 방법이 될 것 같다.
범주 처리2
biograpy는 전기를 말한다. auto가 붙는 것은 해당 인물이 집필에 참여할 때.
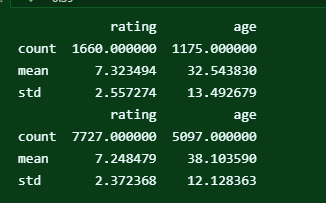
nonfiction과 갑자기 개념이 헷갈려서 한번 비교를 해봤다. nonfiction은 소설 이외의 산문 문학을 말한다. 전기도 충분히 포함되나, 더 포괄적인 개념이라 할 수 있다. 일단 연령대로서는 미약하게나마 차이가 있다. 갯수가 5천 개이기도 해서 biography 역시 따로 한 범주로 묶어도 될 것 같다.

혹시나 싶어 찾아보는데 아주 이상한 녀석이 있다. fiction이면서 biography이기라도 한 거냐..? 모르겠으나, 전기 기반 소설이라고 생각하겠다. 소설 기반 전기는 이상하잖냐. 그렇다면 전기로 분류해도 문제 없을 듯하다.
근데 christian은 조금 마음에 걸린다. 종교물은 종교 관련된 사람들만 읽을 것 같다. 그럼 종교로 묶는 게 선행되는 게 더 맞지 않을까?

종교라 하면 religion이다. 그렇다면 religion으로 묶을 수 있는 다양한 카테고리들을 추려보자. 일단 생각해본 것은 budd(불교 관련), bible(성경), muslim, arab(아랍, 이슬람), christian(기독교), hind(힌두), cath(카톨릭) 이정도.
일일히 찾아봤는데 양이 많지는 않아서 무시해도 될 정도의 것들도 많았다. 아무튼 종교에 대해 읽는 사람들은 어떤 목적이 있을 것이라 생각한다. 그래서 일단 전부 religion으로 퉁쳐보자.

생각해둔 키워드들을 일일히 religion과 비교해봤다. 힌두는 케이스가 3개라 그런지 조금 다른데, 나머지는 대체로 비슷한 것 같다.
한가지 걸리는 것이, bible은 종교 관련 책이 아닌 느낌이 드는 책도 있었다는 것. 이것은 나중에 팀원들에게 물어보는 것으로 하고 일단 진행.

이런 식으로 쓰면 원하는 문자열들을 전부 한꺼번에 바꿔줄 수 있다.
현재까지 정리한 키워드. juvenile, religion, biography

허허, 실수해서 전기를 전부 종교로 치환해버렸다. 재시작.

굳.
다음으로 볼 것은 humor와 history, bodymindspirit.

먼저 humor부터 보자면, 비슷한 단어들 중에 comic은 읽는 연령대가 완전히 달랐고, 이에 차이를 둬야 할 것 같다. 생각해봐야 fun정도나 비슷한 단어인 것 같다. wit도 있다(with나 switchland가 나오기도 해서 뒤에 빈칸을 넣어야 한다.). 사실 유머라고 해도 단순히 웃기는 책이 있을 것이고 사회 비판을 담은 책이 있을 텐데, 풍자나 희화화를 대체로 담는 편에서는 퉁쳐도 될지도.

history를 보려고하는데, 이쪽은 예외가 너무 많다. 역사를 테마로 한 소설, 자연에 대한 역사 등등. 이것은 다른 것들을 처리한 후에 보는 게 좋겠다.

다음은 body, mind, spirit인데, 내가 보기엔 그냥 건강이나 명상 관련으로 보인다. 더 알아듣기 쉽게 meditation으로 퉁치는 것은 어떨까?
body만으로 검색하면 바디빌딩이니, 체력 관련, 보디가드, 보디랭귀지니 그런 게 너무 나오고, mind는 별 다른 게 나오지 않는다. spirit은 다양한 범주가 나오며 비슷한 분류의 책인 듯하다. 여타 다른 유사 키워드는 없는 듯하다.
현재까지 정리한 키워드. juvenile, religion, biography, humor, meditation
다음은 social science. science와 겹칠 수 있기에 social 정도로 바꾸면 좋을 것이다. 사회과학인데,

이런 사회적 관계에 대해 다루는 모든 책을 퉁쳐도 괜찮을 것 같다. 마찬가지로 sociology, society 등의 단어도 묶어도 괜찮을 것 같다.
본격적으로 science를 만지려면 확인할 것이 많다. 일단

SF관련한 것은 200개밖에 되지 않는다. 이것은 그냥 fiction에 같이 넣어도 무방할 것 같다. science에서 가장 많은 것은 사실 social인데, 그것은 방금 뺐고, 그 다음으로는 political이 많다. 거진 700개 가까이 되는데, 따로 분류하는 게 좋을 것 같다. poli관련해서 볼 것이 police. 이 놈은 조금 의미가 달라서 제외해야만 한다. 그러면서 polit, policy는 포함해야 한다..
짜증나게 또 political fiction이 있네..
어떻게 보면 fiction과 관련해 유의미하게 분리해야할 juvenile은 이미 분리했으니 이제부터의 책 분류는 fiction과 fiction 아닌 것으로부터 출발하는 게 나을지도 모르겠다. fiction잡자..ㅋ
키워드 겹치는 범주들이 있어 이 순서들을 고려하는 게 중요한데, 엄밀히 fiction은 juvenile 이후로 바로 잡는 게 나았을 것 같다. 나중에 고칠 필요가 있다.

fiction을 보면, 지역을 기준으로 한 범주들이 꽤나 있는 것이 확인된다. 그 갯수가 2000개에 달한다.
참고로 이런 식으로 코드를 짜서 일일히 확인해보고 있다. fiction과 함께 들어가는 각각의 키워드를 확인해보고 있는데, 유달리 많은 수를 가지는 키워드가 없다. 그러면서 일단은 전부 fiction의 범주에 들어가는 것 같아서 크게 문제삼지 않고 fiction으로 퉁치면 될 것 같다.

200개 정도의 범주가 날아갔다. 속이 다 시원하네.
현재까지 정리한 키워드. juvenile, religion, biography, humor, meditation, social, fiction, politic
다시 science를 잡기 이전에, science에는 computer 관련도 많다. 이것도 어차피 분리할 범주였으니 미리 처리하자.
computer는 굳이 나누지 않아도 전부 말그대로 컴퓨터와 관련된 것들이다.

조금씩 줄어든다.

science 범주에서 뺄 것들을 다 빼버리니 science 자체 말고 남은 것들은 이게 전부다. conscience, 저 녀석은 조금 거슬리기는 한데 나머지는 그래도 science 범주에 들어가도 그러려니 할 수 있을 것 같다.
음.. 기록을 남겨뒀으니 이정도 이상치는 넘어가보자.
다음으로 처리할 것은 business. economics가 붙어있는데, 생각으로는 대충 퉁쳐도 될 것 같다.

business는 범주의 오용이 너무 심하다. 비즈지스를 테마로 하는 소설이 24개 있다. 이들은 fiction으로 분류해주고, 나머지는 그대로 쓰면 되겠다.
economics는 그냥 쓰면 된다.
현재까지 정리한 키워드. juvenile, religion, biography, humor, meditation, social, fiction, politic, computer, science, economy
많이 했다. 이제는 family해보자. family에는 가정 폭력, 가정 레크리에이션 등의 가정과 관련된 것들이 들어가 있는데 충분히 한 범주로 묶어도 괜찮을 것 같다.
self help는 자기계발류의 책인 듯하다. self가 들어가면 웬만해서는 다 이쪽으로 쳐도 될 듯하다. 이놈들을 meditation과 묶는 것은 어떨까?

큰 차이는 없어보인다. 묶자.
health를 찾아보려니 body를 처리해야 할 것 같다. 근데 그러자니 바디랭귀지가 계속 나온다. language나 country를 한번 묶을 필요가 있을 것 같은데, 일단 health에 우겨 넣어볼까..
동물이나 환경 등의 요소도 슬슬 묶어야 한다.
먼저 동물을 묶고, 나머지는 자연, 환경으로 퉁치자. 동물은 애완동물이 있어 합쳐주는 것이 좋을 것 같다.
animal에는 이상한 값이 없고, pet은 pets나 뛰어쓰기를 한번 넣어야 한다.
이외에 dog, cats, bird, insects, tiger, fish 등 다양한 키워드가 있다. 일일히 찾으려니까 조금 힘들다.
이후에는 자연. nature와 environment, plant. 다 퉁치기!
현재까지 정리한 키워드. juvenile, religion, biography, humor, meditation
, social, fiction, politic, computer, science, economy, family, health, animal, nature
다음으로 하려는 것은 history. 이쪽에도 이상값들이 조금 있다. 그러나 이것들은.. 차라리 남겨두고 예외 처리하는 게 편하겠다. 갯수도 적은 편이라 크게 상관은 없을 듯하다. 추가적으로 folk라 하여 민간, 전통 관련 범주를 이쪽으로 넣어주었다.
art. 최소한 우리나라의 범주에서는 예술은 하나로 묶어도 되지 않을까. music, drawing

martial art를 걱정했는데 하나밖에 없기도 하고 죄다 확실히 예술 관련 내용이라 크게 신경쓰지 않아도 될 듯.

꽤 많이 했는데 범주가 끽해야 700개 줄었다.. 내가 생각하던 것보다 범주 데이터는 더러운 것 같다. 내 예상으로는 범주 묶기를 다할 때쯤에는 범주가 세 자릿수로 줄어들 것이라고 봤는데, 전혀 그럴 기미가 보이지를 않는다.
하다가 생긴 의문인데, 언어와 형식이 같이 쓰여져 있다면 무엇을 먼저 고려하는 게 맞을까? 언어? 쓰여진 언어는 분명 먼저 고려돼야 하지만, 내용 상의 언어라면 후로 고려되는 게 좋을 것 같다. 그러나 그것을 이 무더기로 주어진 범주에서 어떻게 구분해낸단 말인가? 아무래도 가정이 필요할 것 같다. 범주에 쓰여진 언어는 쓰여진 언어가 아니라고.

가령 이런 것이다. 포르투갈이라고 범주에 써져 있지만, 사실 영어책인 것.

poetry를 보다가 궁금해진 것. children도 혹시 분류해야할까?
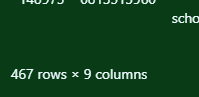
값이 생각보다 많다. 아무래도 이런 건 분류하는 것이 좋겠다. child에 이상한 값은 없어보인다.
이후에 poetry와, drama 분류! 추가적으로 literature관련도 전부 분류했다. literacy와 같이 관련되는 것들을 포함했다!
당장 분류하는 것들은 분류가 힘들도록 이상한 범주가 포함되거나 하는 케이스가 없어서 변경이 빠르게 가능하다. 특이케이스가 없으니 구태여 자세하게 적진 않겠다!
현재까지 정리한 키워드. juvenile, religion, biography, humor, meditation
, social, fiction, politic, computer, science, economy, family, health, animal, nature, history, art, children, poetry, drama, literature, philosophy, cook, crime, photo, hobby

crime에 대해서, 세가지 정도의 나를 귀찮게 하는 책이 있다. social로 넣어주었다. 스페셜 미션에는 homicide를 따로 분류하던데 crime으로 넣어줬다.

취미 범주를 만들었다. craft hobbies, gardening, sport recreation이 여기에 속한다. 근데 craft로 묶으려니 비행기 사고도 엮이는데, 그러고보니 탈 것이나 차, 기계에 대한 책이 많이 존재하지 않는다는 것을 알게 됐다. 왜일까? 1960년대부터 2000년대까지의 시기에 그런 것에 대한 관심이 적진 않았을 것이라 생각하는데. 그나마 transportation은 조금 있다.
아무튼 적은 정도의 오차는 이제 무시하자! hand, craft

travel 범주. time travel.. 장르의 소설도 끼어있다. 3개 정도니 넘어가자.
이후에는 마지막으로 country를 손 봤다. 이것을 하는 게 꽤나 애매했는데, 일단 나라 목록 - 위키백과, 우리 모두의 백과사전 (wikipedia.org) 여기에서 있을 만한 모든 나라를 일일히 검색해가면서 찾고 넣었다. 다만 미국을 제외해서 미국은 따로 범주를 만들었다. 나라 관련 범주를 만드는 것이 맞는 것인지는 모르겠다. 이것은 쉽게 수정이 가능하도록 해두는 것이 좋을 것 같다.
겨우겨우 줄여서 범주가 2600개. 이 이상의 범주 짓기는 너무 비효율적이란 생각이 들어서 범주 내에 데이터가 5개 미만인 놈들을 체크해보니 거의 2000개 가까이 되더라. 그래서 10개 미만의 범주들은 싸그리 others로 날려버렸다.

결과적으로 이정도. 이야.. 더는 힘들어서 못해먹겠는걸. 근데 한편으로 이제는 150개니까 일일히 보면서 할 수 있을 것 같기도.. 으윽.
결측치 처리
결국 이 범주 메꾸는 것은 결측치를 메꾸기 위해서 했던 것이다. 그럼 이 결측치를 이제 어떻게 메꿀 것이냐? 가장 간단한 방법은, 나이 결측치를 메꿀 때의 방법을 그대로 사용하는 것이다.

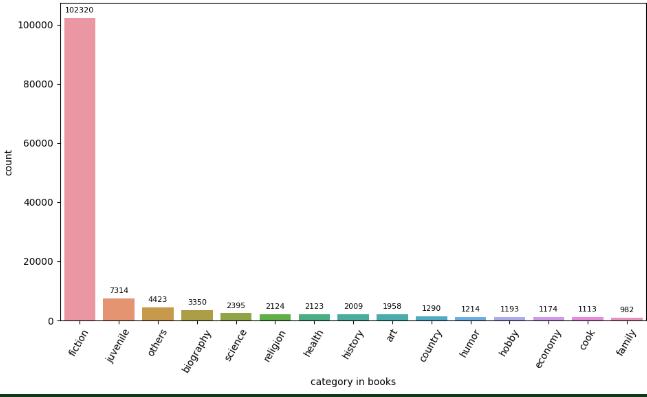
이게 현재 범주 분포에 대한 그래프이다. others가 어마무시하게 많긴 하다.. 저걸 직접 다 처리하려고 했었다니.
하면서 내가 이전에 나이 분포를 where로 바꿀 때 문제가 있었다는 것을 알아냈다. where을 통해 바꾸면, 결측치에 대해 일괄로 choice한 값을 덮어씌우는 모양이다. 내가 나잇값에 대해서 할 때는 잘 됐던 것으로 기억하는데, 제대로 테스트를 해보지 않았던 걸까? 그렇다면 반복문을 돌려서 일일히 확인하면서 메꿔줘야만 하겠지.

바꾼 방식. 무려 20분이 걸렸다. 중간에 잘 되고 있는지 체크하기 위해 print문을 돌게 했는데, 그것 때문에 더 늦어지기도 했던 모양이다.

아무튼 완성된 모양은 이러하다. 범주의 모든 결측치를 일괄적으로 메꾸는 것은 시간이 오래 걸릴 뿐, 어려운 일은 절대 아니다. 생각해보니 apply를 이용해서 결측치일 경우에 값을 바꾸도록 하는 것도 가능하지 않을까 싶네.
회고 및 다짐
처음에는 직접 범주를 만지다보면 빠르게 범주의 갯수가 줄어들 것이라 생각했는데, 너무 오만한 생각이었다. 최소한 내가 범주 지은 방식이 스페셜미션에서 제시한 방식보다는 좋다고 생각하지만, 결국 시간을 너무 많이 소모하고 말았다. 그나마 이게 의미가 있어야만 할 텐데. 정말 의미 있으려면, 저 결측치를 효과적으로 메꾸는 방향이 되어야 한다고 생각한다. 이름과 출판사, 작가의 이름을 통해 결측치를 메꾸는 방법이 있을까? 어떻게? 학습을 통해서?
조금만 더 생각해보자. 일단 내일은 이미지 결측치를 메꿀 방법을 조금 생각해봐야겠다. 내가 보기에는, 이미지는 정말 결측치를 메꿀 방법이 많지 않다. 조금은 줄일 방법이 있을 수도 있다. 아, 그리고 데이터 팀으로서 결측치를 얼추 다 메꾸고 나면 빠르게 모델 팀으로 넘어가서 모델 팀이 하는 일을 도와줘야만 한다.
아는 누나한테 전화가 왔다. 내가 동경하고 또 좋아하는 사람이었는데, 오랜만에 연락이 오니 또 마음이 살짝 떨렸다. 그 시절에 대해서 애매한 감정이 많이 겹쳐있어서 더 갈팡질팡한 것 같다. 일단은, 무엇보다 내가 연락이 두려워 선뜻 먼저 말을 못 꺼내고 아직까지 완전히 인생을 안정권에 두지 못한 데에서 오는 부끄러움이 가장 컸던 것 같다. 어쩔까나, 정말 한번은 내가 용기내서 연락을 해보고 싶다. 과거의 인연을 그만 버리고 싶다.