20221030-7th of Pstage
EDA


어제에 이어 범주를 보는 중. fiction의 종류는 얼마나 되는가 하니, 종류가 꽤나 된다.
오른쪽처럼 소년용 소설이 갯수로 2등을 차지하고 있는 이런 상황에서 fiction이 들어가기만 하면 그냥 죄다 fiction으로 치는 것이 좋은가? 가장 큰 두 범주 간에 연령대 정도는 알아보는 게 좋겠다. 차이가 있다면, 둘을 무작정 합치는 것은 지양해야만 한다.

이 참에 결측률도 같이 보기 위해 결측된 값들을 전부 1로 퉁쳐보았다. 보다시피 결측된 값이 엄청 많다.

학습데이터와 책데이터 간 범주 분포 차이는 생각보다 꽤 크다. 둘다 결측값이 가장 많은 것은 분명하나, 학습셋에서는 똑같은 책을 여러 번 빌리거나, 시리즈 물로 빌리는 경우, 문학 작품에 대해서 다른 책보다 평점을 더 많이 내리는 경우 등의 요인으로 소설에 대한 평점이 굉장히 많은 것을 알 수 있다. 또한 이후 범주들의 분포도 조금씩은 다르다.
범주화 작업을 거친다면 실제로 평점 내려진 책들을 보고 중요도를 고려하는 게 좋을 것 같다. 제대로 빌려지지도 않는 범주의 책을 고려하는 것은 무의미하다.

콜유나 테스트셋의 범주 분포 차이를 보니 학습셋과 비슷해보인다.
일단 책데이터 내의 fiction의 양과 평점관련 데이터들의 fiction의 비율이 다르다는 것은 확인했다.
그리고 결측값은 어떻게 할 것인가? 책에 있어서 중요하게 고려될 결측값이 이렇게나 많아서는 좋은 효과를 보기 힘들 것 같다. 콜유 고려하기 이전에 이 결측값 처리가 우선이 돼야할 것 같다.

의외로 결측률로만 봤을 때는 학습셋의 결측률은 더 낮다.

결측률은 적당한 것 같다.
학습데이터의 범주 별 연령 분포

확실하게 범주 별로 조금씩 연령 차이가 있는 것이 관찰된다. 대체로 2,30대가 가장 많기는 하지만 소설의 경우 50대를 조금 넘은 부분에서 이상치가 도드라지게 발견된다. 청소년용 소설에서는 확실하게 10대에게 인기가 있는 것이 보인다. 요리 관련해서는 10대가 50대 이후 사람들은 확실히 수요가 없다.
이쪽에 대해서는 분명한 차이가 존재하는 것 같다. 지금 드는 생각으로는 이런 차이들이 고려될 수 있도록 확실하게 범주를 묶어주어야만 할 것 같다. 소설과 청소년용 소설은 차이가 꽤 있는 편이며 그냥 소설로 퉁쳐버리기에는 너무 아까운 것 같다.
콜유의 범주 별 연령 분포

이쪽을 파고들기 시작하니까 조합할 수 있는 것이 너무 많다. 아무튼, 일단 콜유에서는 청소년물은 청소년들이 확실하게 많이 보는 것이 확인되고 있다.
이것으로 무엇을 볼 수 있을까? 콜유가 빌린 책의 분포를 확인하고
각 연령대가 주는 평점의 평균?
카테고리 별로 각 연령대가 주는 평점의 평균?
팀 미팅
데이터
데이터셋의 문제점. 콜드 스타트, 결측치, 쓰레기값(의미없는 범주). 데이터 불균형이 존재한다.
그래서 세세한 것에 대해서는 제대로 학습이 되지 않을 것 같다.
샘플링할 때 밸런스를 맞출 수 있지 않을까?
범주 별로 평점을 내린 유저의 나이 분포가 저마다 다르다.
모델
다들 전처리가 쓰는 게 지 맘대로다. fm,ffm은 모델 별로의 특징이 잘 드러나지 않음.

deep conn은 책의 요약 데이터에 대해 합성곱을 하는데 이게 의미가 있나! 해서 다르게 바꾸는 것도 방법. 전처리가 되고 나서 본격적으로 모델을 돌려보는 게 좋을 것 같다.
DeePCoNN은 결국 CNN_FM과 조금 비슷함. DCN이 WDN보다는 좋다.
해야할 것
결측치 채우기. 무얼 어떻게 채울 것인가? 범주, 나라, 언어, 나이. 이중에서 범주와 나이가 결측률이 높고, 이들을 처리하는 게 결측치 채우기의 핵심이 될 것이다.
범주 군집화. 범주는 이웃한 책으로서의 의미를 가장 크게 가진다고 생각한다. 이것을 잘 군집화시키는 것이 큰 포인트가 될 것이다.
쓰레기값 처리. 이것은 사실 어떤 것이 쓰레기인지 우리가 판단하기 쉽지 않다. 나중에 모델팀이 테스트할 수 있도록 환경만 지원해주면 될 듯하다.
다시 EDA
조금 더 목표를 가지고 EDA를 진행하면서, 어떻게 결측치에 대한 전처리를 하면 좋을지 생각해보자.
나이를 어떻게 메꿀 것인가? 이전에 나는 전체 유저의 나이 분포를 확인하고 그것을 그대로 확률 분포로 활용해 결측값을 메꿔주었다.

베이스라인의 코드에서는 단순하게 평균을 내서 값을 메꿔주는 것을 확인할 수 있다.
혹 나이대 별로 평점을 다르게 내리지는 않을까? 이것을 확인한다면 이를 고려해서 학습셋의 평점을 메꿔줄 수 있다.
다만 이러한 방법은 테스트셋 유저에 대한 결측을 채워줄 수는 없다. 콜유가 존재하기 때문이다.
그보다는 빌리는 책의 정보를 토대로 평점을 매겨주는 게 좋지 않을까 한다. 그러나 그렇다면 다시 부딪치는 문제가 있으니, 바로 범주를 어떻게 보완할지.

범주의 갯수는 3716개, 그 중에 단일한 범주의 갯수는 1843개이다. 이 놈들은 확실하게 처리해버리는 것이 낫다. 이름들을 봤을 때, 키워드를 통해서 범주를 묶을 때 적당히 걸러지는 것들도 있을 것으로 보인다.

그러나 스페셜 미션에서 제공하는 방법은 그다지 좋지 못한 것이, 특정 단어가 포함되기만 하면 전부 그것으로 퉁쳐버리기에 fiction이란 말이 들어가는 모든 범주가 fiction으로 바뀐다. 뒤에 science fiction이니 하는 것들은 저 반복문을 돌면 싹 날아가버린다.

이렇게. nonfiction이나 juvenile fiction의 경우는 수도 많고, 위에서 보는 나이대가 다르다는 것도 확인했기에 그저 fiction이라고 퉁쳐지기에는 너무 아쉬운 범주라고 생각한다. 그래서 이보다 더 좋은 방법이 필요하다.

대체 bird는 왜 따로 두는 거냐? 혹시 뭐가 있나? bird에 해당하는 학습 세의 행을 살펴봤지만, 아무리 봐도 bird를 따로 둬야 할 이유는 보이지 않는다.
지금 보면서 드는 생각으로, 내가 직접 그냥 범주를 나누는 게 좋겠다. 제공된 범주 분류는 오히려 학습을 방해할 수도 있다고 생각한다. 중요하지 않을 정보를 남기면서 오히려 중요한 정보를 말소시키고 있다.
그러면 어떻게 매길까? 갯수를 고려해서 나누는 것이 좋다고 본다. 근데 이 갯수는 단순히 책 데이터만 보지 말고, 학습 데이터에서도 접근해야 한다. 결국 우리가 학습할 평점은 학습데이터에 있으니까.


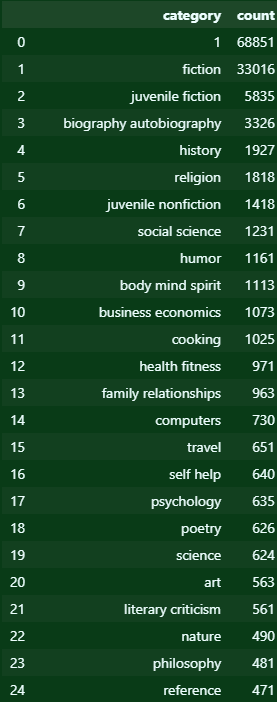



봐야할 것이 너무 많다. 고민하다가, 일단 상위권에서 처리할 놈들을 따로 정하고 그놈들을 줄여나가면서 더 찾아보기로 마음 먹었다. 보다시피 상위 20개의 범주에서부터는 지분이 급격하게 낮아진다. 그렇다면 이놈들을 기준으로 먼저 정제를 해보자고.


상위권에 위치한 juvenile 시리즈 두 개. 내 생각에는 fiction nonfiction의 여부는 그다지 중요해보이지 않는다. 책들이 어떤 것들이 있는지도 확인해봤는데, 둘을 합쳐도 괜찮지 않을까 싶다. 내가 일부러 데이터의 의미를 부각시키는 방향이 될 듯하다. 평균 세 살 차이가 조금 걸리기는 한데, fiction자체는 평균이 37이 나오는데, 그것보다는 낫지 않나, 하는 생각이다.
범주 관련을 알아보면서 당부해야 할 것 같은 것이, 책의 범주가 모호한 것을 내가 전부 해결할 수는 없다는 것. 어떤 것은 쓸데없이 세분화되어있고, 어떤 것은 내용적 특성을 범주로 담느라 형식을 고려하지 않는 등 다양한 문제가 있다. 가령 criminal이라 써있길래 범죄 관련 정보를 전달하는 글인가 했더니 올리버 트위스트의 소설인 경우도 있었다. 그럼 fiction에 들어갈 것이지 왜 따로 튀어나와있냐구..
어라. 그럼 내용에 따른 범주 따로 형식에 따른 범주 따로? 음. 이건 너무 어려운 일이 될 것 같다.
일단 이 작업을 끝내면 나이 결측치를 채우기보다 범주 결측치를 먼저 채워야겠다. 내가 보기에 사실 베스트는 이걸 우리가 직접 하지 않고 학습 모델을 만들어서 학습을 시킨 뒤에 알아서 채워넣게 하는 것이다. 여태 배운 것들을 활용하면 얼마나 좋냐. 다만 그것을 만들기 위해 시간을 쓰다가 이 프로젝트 기한 내에 원하는 결과를 내지 못할까 두려워 보류하겠다.
회고 및 다짐
잠을 통 못 자서 근래 몸이 피로하다보니 마음도 조금 해이해지려고 한다. 중간에 힘들어서 누워있는다는 게 순식간에 몇 시간을 자버렸더라고. 이정도면 적당한 휴식이었노라 생각하고 다시 힘을 내야겠다. 해보고 싶은 것은 아직 많다. 일주일의 시간만 더 있다면 그래도 해보고 싶은 것들을 다 해볼 수 있을 것 같은데, 시간에 쫓기는 느낌은 지울 수가 없다. 인생에 타임 외치는 게 어딨냐, 그런 시간은 전역하면서 날려먹었다. 결국 내가 시간을 자유롭게 조정할 수 없는 이상 내가 그 시간에 맞춰야만 한다.
지금 힘들게 해둘수록 나중에 얻는 것은 더 많기 마련이다. 지금 많이 해둘수록 나중에 더 다양하게 할 수 있다. 벌써 나는 내가 이전보다 조금은 더 성장했음을 느낀다. 이 성장의 기쁨을 동력으로 계속 나아가야만 한다.
흐뜨러지지 않도록 조심하자. 안일함으로 너무 많은 일을 그르쳤다. 사실 지금도 이러면 어떠하고 저려면 어떠하겠냐는 마음이 스멀스멀 기어올라오기도 해서 계속 이제는 이것밖에 없다는 절박함을 주입시킨다. 의지가 있기에 더 극한으로 밀어넣으려고 하는 것이지만, 그렇게 극한에 상황에 놓여야 필사의 의지가 피어오른다. 애매한 순환 구조가 있어서, 계속 페달을 밟아줘야 하긴 하지만 그래도 지속한다면 제법 속도가 붙을 것이다. 그리고 처음 밟을 때보다 힘은 덜 들기 마련이다. 지금은 살짝 오르막길에 다다른 것이다. 더 밟아야지 속도를 잃지 않고 나아갈 수 있다. 평지로 올라섰을 때 잠시 다리를 쉬어주자고, 지금은 악깡버해야 할 시기이다!